
📝 ملخص كورس علم البيانات - 12
الدرس الثاني في التعلم غير الموجَّه يتحدث عن التجميع Clustering بأشكال أخرى.
الفصل الثالث - التعلم غير الموجَّه Unsupervised Learning
الدرس الثاني - التجميع القائم على الكثافة والهرمية - Hierarchical and Density Based Clustering
التجميع الهرمي Hierarchical Clustering
كتبت سابقاً عن التجميع الهرمي. وشرحت طريقتها كالتالي:
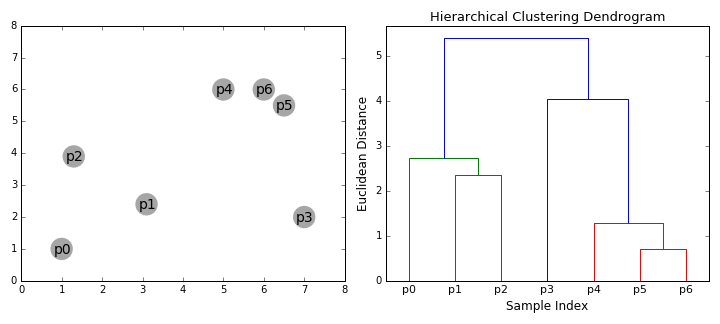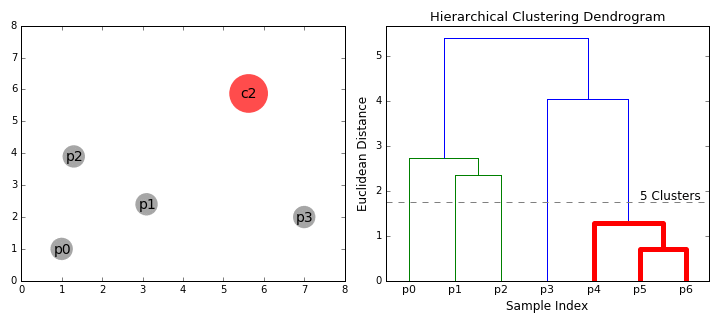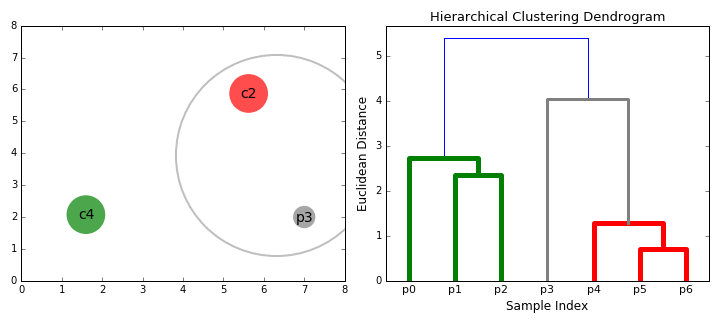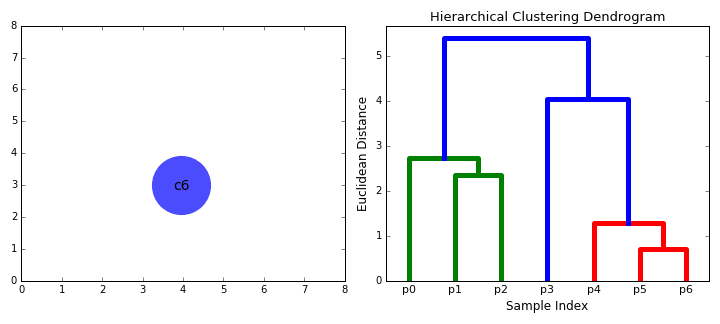
- التجميع الهرمي يُكَوِّن مجموعة أو Cluster لكل نقطة لدينا.
- يتم جمع أقرب نقطتين مع بعضهم البعض وتُكَون مجموعة جديدة.
- تبحث الخوارزمية عن نقطة أخرى قريبة لها وتضمها إلى نفس المجموعة Cluster.
- تستمر الخوارزمية بعمل الخطوتين السابقتين إلى أن تبقى مجموعة واحده Cluster تُجمع فيها كل النقاط.
أنواع التجميع الهرمي:
توجد أربع أنواع لتحديد المسافات بين الـClusters في التجميع الهرمي: 1
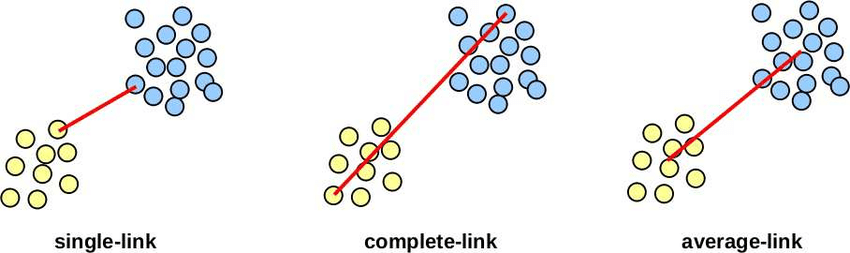
- Single Link: تحدد المسافه بين كل Cluster وأخرى عن طريق حساب أقرب نقطتين لبعضها البعض في كل Cluster.
- Complete Link: تحدد المسافه بين كل Cluster وأخرى عن طريق حساب أبعد نقطتين لبعضها البعض في كل Cluster.
- Average Link: تحدد المسافه بين كل Cluster وأخرى عن طريق حساب متوسط المسافه بين كل النقاط في كل Cluster.

- Ward’s Method: على عكس الطرق السابقة، طريقة Ward’s تقوم بتكوين نقطة مركزية Centroid بين مجموعتين Clusters، بعد ذلك تحسب المسافة من النقاط إلى النقطة الجديدة التي أوجدتها سابقاً، تربع المسافه السابقة لكل نقطة ثم تُجمع جميعها. بعد ذلك نقوم بتربيع ثم طرح المسافة بين كل نقطة والنقطة المركزية في الـCluster الخاص بها.
كود بايثون
تطبيق عملي في بايثون للتجميع الهرمي
from sklearn.cluster import AgglomerativeClustering
from sklearn.metrics import adjusted_rand_score
from sklearn import preprocessing
from scipy.cluster.hierarchy import linkage
from scipy.cluster.hierarchy import dendrogram
import matplotlib.pyplot as plt
from sklearn import datasets
# تحميل البيانات، في هذه المثال استخدمنا بيانات مرفقة من Scikit-learn
# بأسم Iris
iris = datasets.load_iris()
# ننشأ المودل ونعطية عدد الـClusters
# النوع التلقائي المستخدم من المكتبة هي Ward's Method
# إذا اردنا إختيار نوع مختلف من الأربعة التي ذكرت سابقاً
# نضيف الخيار linkage
# ونعطية أحد الخيارات التاليه:
# “ward”, “complete”, “average”, “single”
# مثال:
# AgglomerativeClustering(n_clusters=3, linkage='complete')
ward = AgglomerativeClustering(n_clusters=3)
# الربط والتوقع بدالة واحدة fit_predict
ward_pred = ward.fit_predict(iris.data)
# لتقييم المودل ومعرفة دقته
ward_ar_score = adjusted_rand_score(iris.target, ward_pred)
# النتيجة: 0.73119
# لتحسين النتائج أو إذا كانت لدينا فروقات كثيره بين البيانات من
# الممكن أن بالـ Normalizing
# راجع الجزء 11 لشرح عن Normalization
normalized_X = preprocessing.normalize(iris.data)
# النتيجة: 0.88569
# لعرضها بشكل رسم بياني نقوم بالتالي
linkage_type = 'ward'
linkage_matrix = linkage(normalized_X, linkage_type)
plt.figure(figsize=(22,18))
dendrogram(linkage_matrix)
plt.show()
التجميع القائم على الكثافة Density Based Clustering
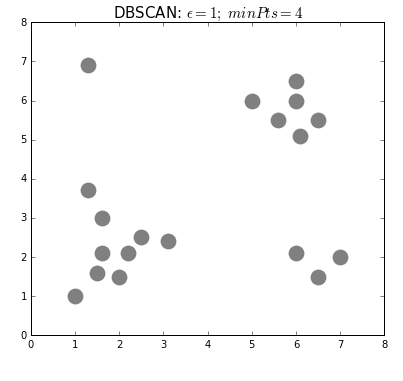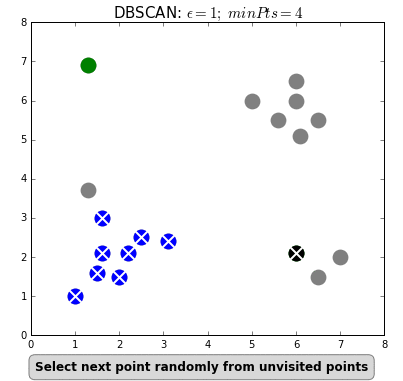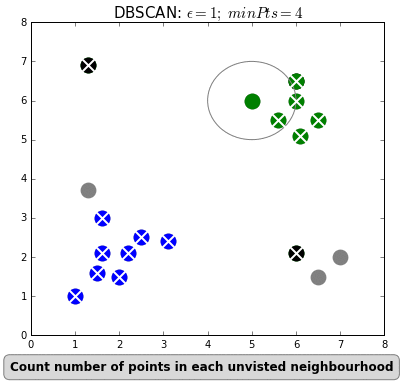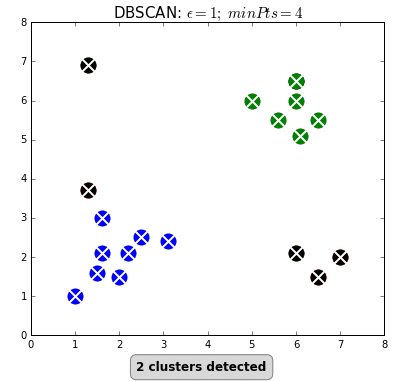
طريقة عملها كالتالي: 2
- قبل انشاء المودل نعطيه بعض المتغيرات
- عدد النقاط في كل Cluster أو min_samples
- المسافة بين كل نقطة وأخرى Epsilon ε
- نبدأ من نقطة معينة ونرى إذا كان هناك نقاط اخرى في المسافة التي حددناها ε
- اذا لم يكن هناك نقاط أخرى، تحسب هذه النقطه كنقطة مزعجة ويتم تجاهلها.
- اذا كان هناك نقاط أخرى ومجموعها أقل من الحد الادنى لعدد النقاط الذي حددناه، نتجاهل هذه النقاط وننتقل لأي نقطة قريبة أخرى
- أذا وجد نقاط أخرى ومجموع النقاط أعلى أو يساوي العدد الذي حددناه، نقوم بإنشاء Cluster هنا، في حال وجدت نقاط أخرى توافي نفس الشروط بالحد الادنى والمسافة وفي نفس الـ Cluster لهذه النقطة، نجمعها جميعاً في Cluster واحد.
مثال بايثون
مثال عملي لطريقة إنشاء مودل للتجميع القائم على الكثافة
from sklearn.cluster import DBSCAN
# لتكن لدينا بيانات معرفة في المتغير data
data = data
# ننشأ المودل ونحدد المسافة eps
# والحد الادنى من النقاط min_samples
dbscan = DBSCAN(eps=3, min_samples=2)
# الربط والتوقع بدالة واحدة fit_predict
# النتيجة -1 تعني ان القيمة مزعجه وتم تجاهلها
clustering_labels_1 = dbscan.fit_predict(data)
العودة إلى ملخص كورس علم البيانات - 11 - الإنتقال إلى ملخص كورس علم البيانات - 13
كُتب في 13/04/2019