
📝 ملخص كورس علم البيانات - 11
الجزء الثالث من الكورس يتكلم عن التعلم غير الموجَّه Unsupervised Learning.
الفصل الثالث - التعلم غير الموجَّه Unsupervised Learning
الدرس الأول - التجميع - Clustering
كتبت في منشور سابق عن التعلم غير الموجَّه بشكل عام، تعريفة وأمثله عليه واشهر خوارزمياته.
أنواع التعلم غير الموجَّه
- Clustering التجميع: جمع البيانات على شكل فئات حسب خصائص معينه تتاشبه فيها.
- Dimensionality reduction تقليص الأبعاد: عرض البيانات بأقل عدد من الخصائص.
ويضاف لها أحياناً: - Association Rules قواعد / قوانين الربط: ربط البيانات فيما بينها عن طريق محاولة أكتشاف علاقات بينها.
خوارزميات التعلم غير الموجَّه
K-Means تجميع بالمتوسطات
 تم شرحها سابقاً بشكل مفصل هنا. تستخدم هذه الخوارزمية كثيراً في برامج تقديم الإقتراحات مثلاً في Netflix و Spotify.
تم شرحها سابقاً بشكل مفصل هنا. تستخدم هذه الخوارزمية كثيراً في برامج تقديم الإقتراحات مثلاً في Netflix و Spotify.
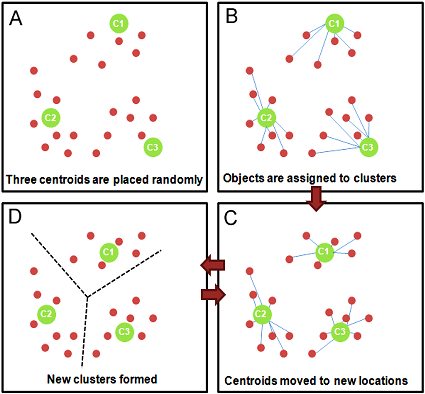
طريقة عمل الخوارزمية K-Means
- يتم إعطاء الخوارزمية رقم K ويعني عدد مرات تقسيم (تجميع) البيانات إلى Clusters.
- بنفس الرقم K يتم رسم نقاط تعرف بالنقاط المركزية Centroids.
- تربط كل بيانات بما يقارب لها من نقاط مركزية.
- تقوم الخوارزمية بحساب المتوسط لجميع النقاط داخل كل Cluster.
- تكرار الخطوتين الأخيرتين مرة أخرى حتى تصل لنقاط مركزية وتجميعة مناسبة لجميع النقاط.
Elbow Method
طريقة لإيجاد عدد الـK في خوارزمية K-Means، و K تعني هنا عدد الـClusters في البيانات لدينا. تستخدم هذه الطريقة عندما لا نعرف عدد التصنيفات لدينا. طريقة عملها كالتالي:
- نتبع الخطوات السابقة لعمل الخوارزمية
- عند انشاء الخوارزمية بواسطة Scikit-learn يحتوي المودل على دالة Score
- نظهر النتائج في رسم بياني يكون شكله كالتالي
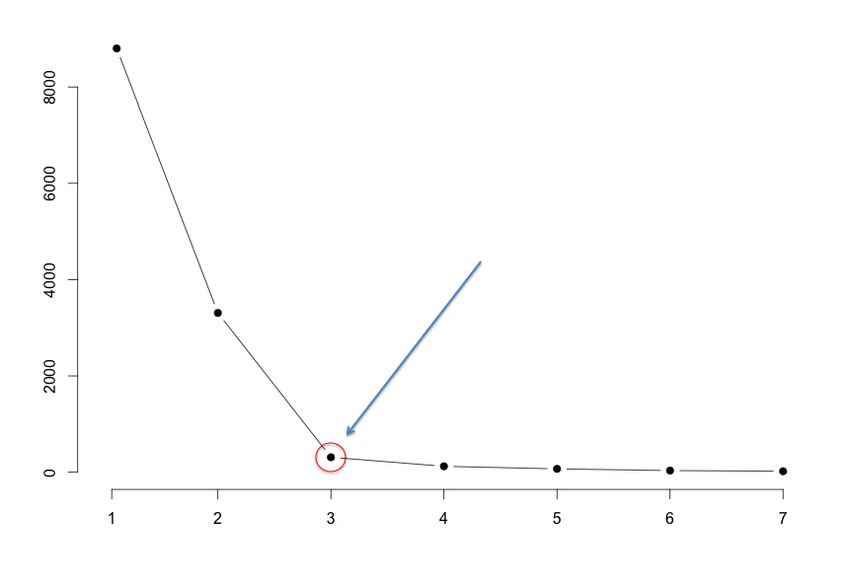 X = Number of K & Y = Average Distance to Cluster 1
X = Number of K & Y = Average Distance to Cluster 1 - في الصورة العلوية، 3 هو العدد المناسب الذي يتوقف فيه التغير العالي في متوسط المسافة بين النقاط و الـCluster.
مثال بايثون
طريقة كتابة خوارزمية K-means وإستخدام الـElbow Method
from sklearn.cluster import KMeans
import numpy as np
import matplotlib.pyplot as plt
# لنفرض لدينا بيانات معرفة في data
data = data
# نعرف المودل ونضيف له عدد الClusters
kmeans_4 = KMeans(n_clusters=4)
# نقوم بربط البيانات مع المودل
model_4 = kmeans_4.fit(data)
# للتوقع نقوم بالتالي
labels_4 = model_4.predict(data)
# الجزء التالي لعرض Elbow method كرسم بياني بإستخدام مكتبة matplotlib
# هنا نجرب من 1 إلى 10 Clusters ونظهر نتائجها
No_of_clusters = range(1, 10)
# ننشأ قائمة تحتوي على 10 مودلز من 1 إلى 10 Clusters
kmeans = [KMeans(n_clusters=i) for i in No_of_clusters]
# ننشأ قائمة ثانية تحتوي على نتائج كل مودل من التي أنشئناها بالخطوة السابقة
score = [np.abs(kmeans[i].fit(data).score(data)) for i in range(len(kmeans))]
# عرض النتائج في رسم بياني
plt.plot(No_of_clusters, score, linestyle='--', marker='o', color='b');
plt.xlabel('Number of Clusters')
plt.ylabel('Score')
plt.title('Elbow Curve')
plt.show()
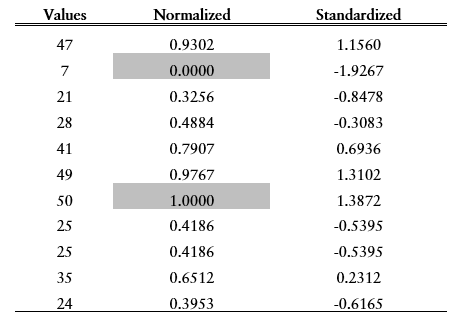
Feature Scaling
طريقة لإعادة تعين قيمة النتائج حتى نحصل على بيانات ونتائج صحيحة، توجد طريقتين لذلك:
- Standardizing: تحويل القيم إلى رقم جديد يكون متوسط Mean كل النتائج يساوي 0 وتباين Variance يساوي 1. تكون النتائج عادة متقاربة من -3 إلى 3 مثلاً.
- Normalizing: تحويل القيم إلى رقم جديد من 0 إلى 1.
مثال لنتائج قبل وبعد التحويل لإحدى الطريقتين: 2
العودة إلى ملخص كورس علم البيانات - 10 - الإنتقال إلى ملخص كورس علم البيانات - 12
كُتب في 11/04/2019