
📝 ملخص كورس علم البيانات - 13
الدرس الثالث يتحدث عن خوارزمية Gaussain Models والتحقق من النتائج وطريقة المقارنة بين مختلف الخوارزميات في التجميع
الفصل الثالث - التعلم غير الموجَّه Unsupervised Learning
الدرس الثالث - Gaussian Mixture Models and Cluster Validation
Gaussian Mixture Models (GMM)
خوارزمية تجميع، مشابهه لـK-mean ولكن تأخذ بعين الإعتبار التباين. وسنستخدم فيها الـGaussian وهي طريقة لرسم البيانات وفهم الخوارزمية لكيفية تشكيل البيانات لدينا.
- Mean المتوسط: وهو دائماً يكون في وسط الـCluster.
- Variance التبيان: ويشكل طريقة توسع البيانات في الـCluster.
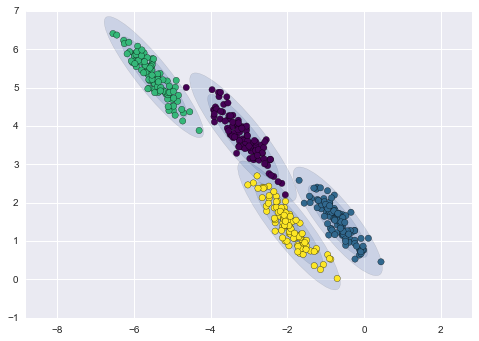
على سبيل المثال، الصورة التالية كونت 4 Clusters وكما يظهر لنا طريقة توسعها بسبب عمل الخوارزمية على المتوسط والتبيان لتشكيل الـClusters، على عكس ما كانت عليه خوارزمية K-mean التي تأدي عملها افضل على البيانات ذات الشكل الدائري. 1
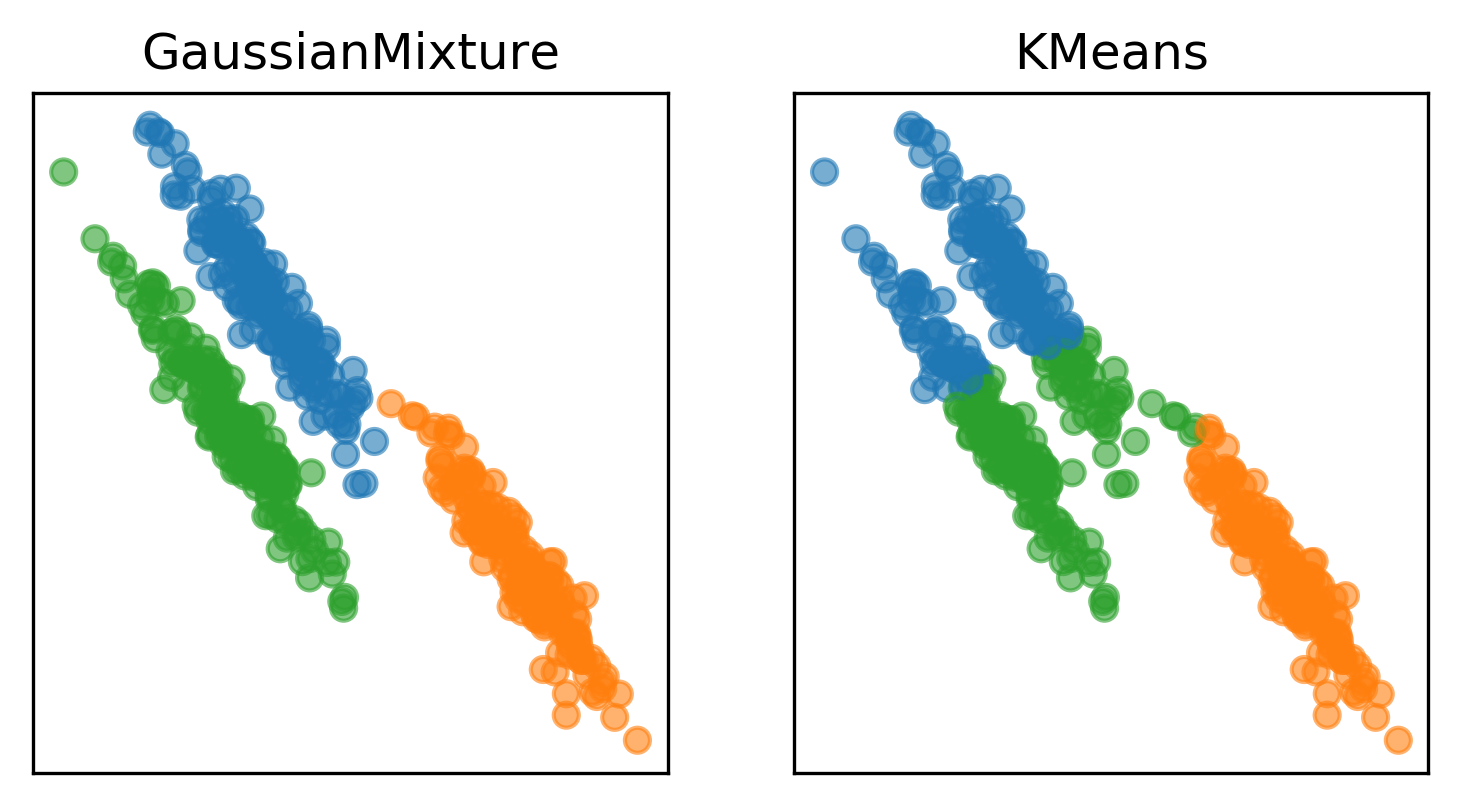
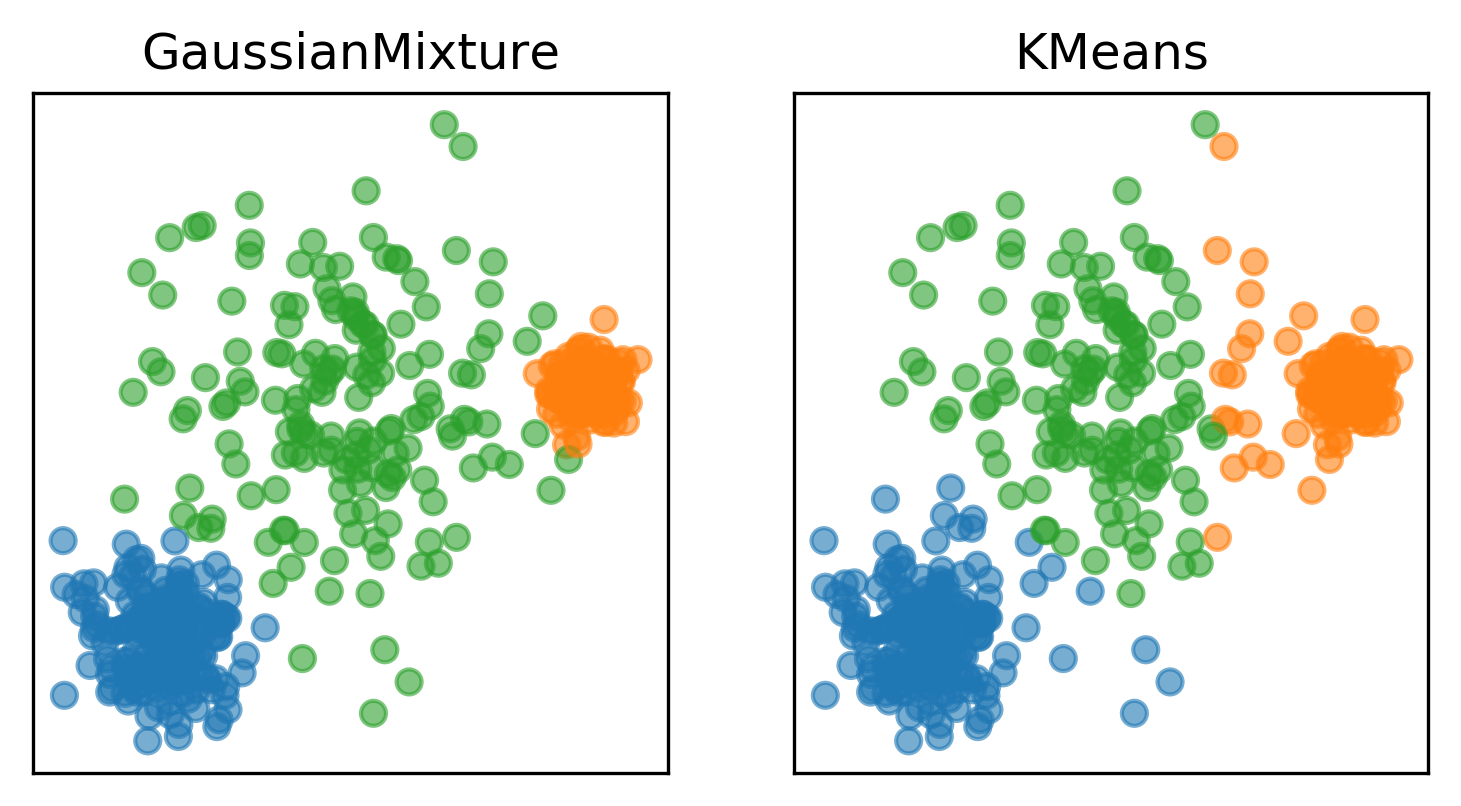
مثال أخر للفرق في تكوين الـClusters في K-mean و GMM 2
Expectation Maximization (EM)
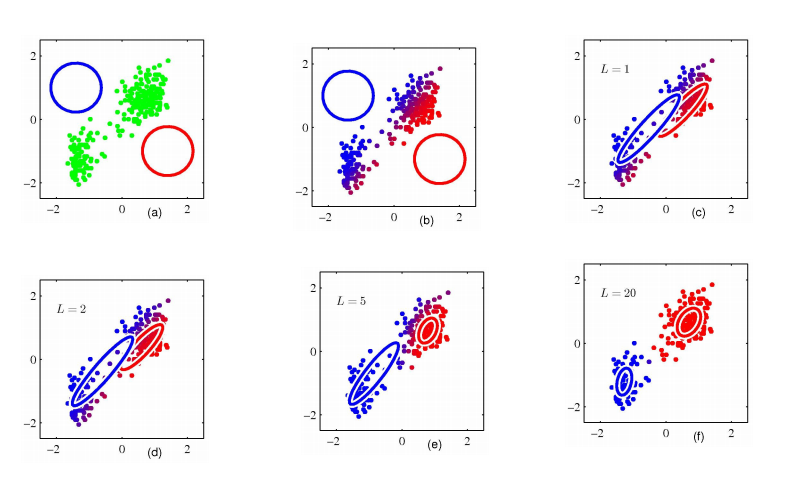
طريقة تتبع في خوارزمية GMM وطريقتها كالتالي: 3
- اختيار K كعدد للـ Clusters وأختيار نقاط بداية عشوائية.
- نحدد لكل نقطة في البيانات Cluster خاص بها.
- نحسب المسافة والتبيان بين كل نقطة والنقطة المركزية، ثم نقوم بتغير موقع النقطة المركزية، ثم إعادة الحساب للمتوسط والتباين.
- اذا توقف التغير في المتوسط يتم إختيار المنطقة كنقطة مركزية جديدة.
طريقة تحليل الـ Clusters
- Feature Selecting: اختيار المتغيرات او الخصائص المناسبة وتوجد طرق لإختيار الأفضل.
- Clustering Algorithm: اختيار الخوارزمية المناسبة في التجميع وإعادة ضبطها حتى نصل لنتائج مرضية.
- Clustering Validation: التحقق وعرض النتائج وتقيمها.
Cluster Validation
في التعليم الموجَّه كانت لدينا خيارات تقييم للمودل كـ Accuracy و الـPrecision، في التعلم غير الموجّّه توجد ثلاث خيارات لتقييم الـCluster وهي: 4
- External Index: يتم فيه مقارنة النتائج في الـCluster مع النتائج الصحيحة (Labels) المعروفة مسبقاً.
- Internal Index: يتحقق من النتائج للـCluster بدون الإعتماد على النتائج الصحيحه (ان لم تكن موجودة مثلاً).
- Silhouette Coefficient: طريقة لحساب اداء الـCluster اذا لم تكن هناك نتائج (Labels) والمعادلة الخاصة بها كالتالي:
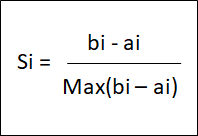
- a = معدل المسافة من نقطة إلى النقاط الاخرى في نفس الـCluster.
- b = معدل المسافة من نقطة إلى النقاط الأخرى في أقرب Cluster لللتي تحتوي على نقطتنا الحالية.
نكرر هذه العملية على كل نقطة لدينا، ثم نجمع النتائج ونأخذ المعدل. وهو بالغالب رقم من -1 إلى 1. 5
ملاحظة: لا تستخدم هذه العملية مع Density-Based Clustering لأنها تعطي نتائج خاطئة.
- Silhouette Coefficient: طريقة لحساب اداء الـCluster اذا لم تكن هناك نتائج (Labels) والمعادلة الخاصة بها كالتالي:
- Relative Index: تقارن بين اثنين من الـClusters.
مثال بايثون
مثال لطريقة إنشاء مودل بخوارزمية GMM
from sklearn.mixture import GaussianMixture
data = data
# ننشأ المودل ونحدد عدد الـCluster 3
gmm = GaussianMixture(n_components=3)
# الربط والتوقع
gmm = gmm.fit(X)
pred_gmm = gmm.predict(X)
العودة إلى ملخص كورس علم البيانات - 12 - الإنتقال إلى ملخص كورس علم البيانات - 14
كُتب في 15/04/2019