
📝 ملخص كورس علم البيانات - 3
هذا الملخص سيكون عن خوارزمية بايز البسيط Naive Bayes، فكرتها وإستخدامتها، طريقة إٍستخدامها في مكتبة scikit-learn وبعض المتغيرات المهمه فيها، وطريقة تقييم المودل ونتائجه.
الفصل الأول - التعلم الموجَّه Supervised Learning
الدرس الخامس - خوارزمية بايز البسيط Naive Bayes
من اشهر استخداماتها في تحديد ما اذا كانت رسالة البريد الإلكتروني مزعجة أو لا. ارفقت في اسفل الصفحة مصادر لمعرفة المسائل الرياضية خلف هذه الخوارزمية. 1 2 More info in jupyter notebook file.
Bag of words
استخدمت في مودل تحديد الرسائل اذا كانت مزعجة أو لا. وهي نفس الفكرة التي شرحت سابقاً في Decision Tree: One-hot encode.
هنا الطريقة تكون بتحويل كل كلمة إلى عامود. وفي كل مرة تتكرر الكلمة يضاف 1 إلى ذلك العامود، مثال لدينا الجمل التالية:
[‘Hello, how are you!’,
‘Win money, win from home.’,
‘Call me now’,
‘Hello, Call you tomorrow?’]
بعد تحويلها تصبح بهذا الشكل:
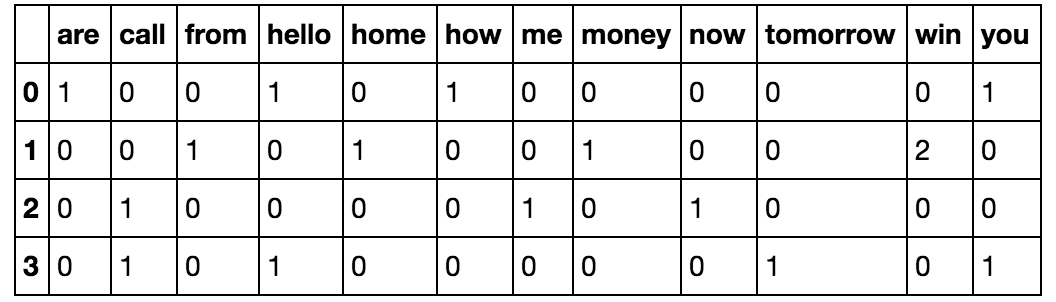
تتم هذه العملية بواسطة دالة CountVectorizer في scikit-learn، معلومات مهمة في عمل الدالة:
- الدالة تحول الكلمات إلى Lowercase إلا اذا تم إلغاء هذا الشرط.
- الدالة أيضاً تحذف علامات الترقيم مثل !.
- المتغير stop_words في حال تحديد اللغة للإنجليزية يحذف الكلمات الأكثر تكرار مثل and, the, an وغيرها.
الكود التالي لطريقة التحويل
from sklearn.feature_extraction.text import CountVectorizer
documents = ['Hello, how are you!',
'Win money, win from home.',
'Call me now.',
'Hello, Call hello you tomorrow?']
# create CountVectorizer instance and fit it to our list
count_vector = CountVectorizer()
count_vector.fit(documents)
# transform it to array
doc_array = count_vector.transform(documents).toarray()
# transform array to dataframe
frequency_matrix = pd.DataFrame(doc_array)
# change column names to words
frequency_matrix.columns = count_vector.get_feature_names()
frequency_matrix
خطوات تشكيل المودل
- تقسيم البيانات إلى بيانات أختبار وبيانات تدريب train_test_split
X_train, X_test, y_train, y_test = train_test_split(df['sms_message'], df['label'], random_state=1) # calculate the size of our dataframe print('Number of rows in the total set: {}'.format(df.shape[0])) print('Number of rows in the training set: {}'.format(X_train.shape[0])) print('Number of rows in the test set: {}'.format(X_test.shape[0]))بعد تقسيمها، نحولها للشكل المطلوب بإستخدام CountVectorizer:
count_vector = CountVectorizer() training_data = count_vector.fit_transform(X_train) testing_data = count_vector.transform(X_test).toarray()بعد تعديلها، نستخدم المصنف (Classifier) MultinomialNB كونه مناسب للبيانات المفصلة. بينما Gaussian Naive Bayes منسابة للبيانات الرقمية المتسلسلة.
from sklearn.naive_bayes import MultinomialNB
naive_bayes = MultinomialNB()
naive_bayes.fit(training_data, y_train)
predictions = naive_bayes.predict(testing_data)
تقييم المودل
- Accuracy: يحدد عدد المرات التي كانت إجابة المُصنف (Classifier) صحيحه.
Accuracy measures how often the classifier makes the correct prediction. It’s the ratio of the number of correct predictions to the total number of predictions (the number of test data points). - Precision: يحدد نسبة مدى دقة المُصنف في توقعاته الصحيحه.
Precision tells us what proportion of messages we classified as spam, actually were spam. It is a ratio of true positives(words classified as spam, and which are actually spam) to all positives(all words classified as spam, irrespective of whether that was the correct classification), in other words it is the ratio of
[True Positives/(True Positives + False Positives)] - Recall(sensitivity): يحدد نسبة البيانات التي حددناها نحن كمزعجه (في مثال رسائل البريد الإلكتروني)
Recall(sensitivity) tells us what proportion of messages that actually were spam were classified by us as spam.
It is a ratio of true positives(words classified as spam, and which are actually spam) to all the words that were actually spam, in other words it is the ratio of
[True Positives/(True Positives + False Negatives)] - F1 Score: وتعني النتيجة الكاملة لكفائة ودقة المودل. في هذا المثال النتيجة كالتالي:
F1 Scode = 2 * ( (*Precision* * *Recall*) / (*Precision* + *Recall*) )
from sklearn.metrics import accuracy_score, precision_score, recall_score, f1_score
print('Accuracy score: ', format(accuracy_score(y_test, predictions)))
print('Precision score: ', format(precision_score(y_test, predictions)))
print('Recall score: ', format(recall_score(y_test, predictions)))
print('F1 score: ', format(f1_score(y_test, predictions)))
العودة إلى ملخص كورس علم البيانات - 2 - الإنتقال إلى ملخص كورس علم البيانات - 4