
📝 ملخص كورس علم البيانات - 4
هذا الجزء سيكون عن آلة المتجهات الداعمة Support Vector Machines، متى تستخدم، والمتغيرات فيها وطريقة تكوين النموذج الخاص فيها ببايثون.
الفصل الأول - التعلم الموجَّه Supervised Learning
الدرس السادس - آلة المتجهات الداعمة Support Vector Machines 1
تعتبر من أكثر الخوارزميات استخداماً في التصنيف، وتقوم الخوارزمية بالبحث عن افضل طريقة لتقسيم البيانات. بحيث تحاول تكوين أكبر مسافه بين القيم. سبق أن تحدثت عنها هنا
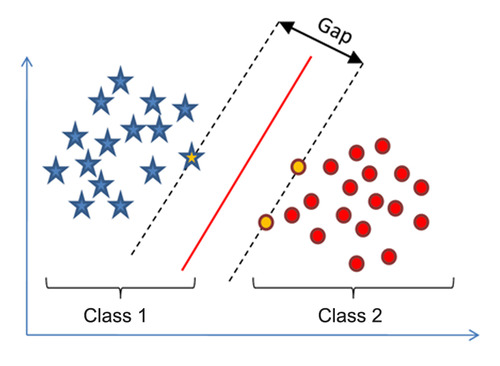
Error Function
Small margin > large error
Large margin > small error
وللتقليل من الاخطاء نستخدم Gradient Descent
Hyperparameters المتغيرات 2
- The C parameter
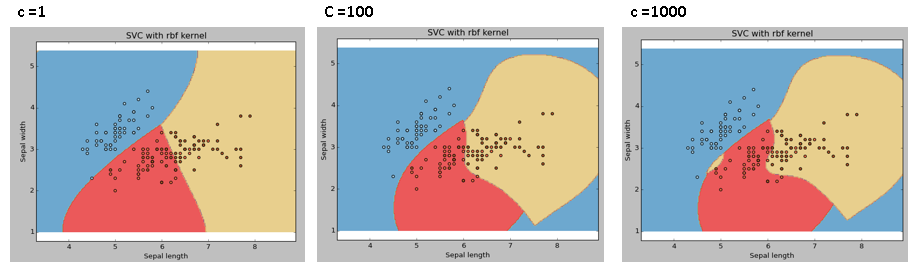
- Large C: Focus on classifying points.
- Small C: Focus on a large margin.
- Kernels 3 4
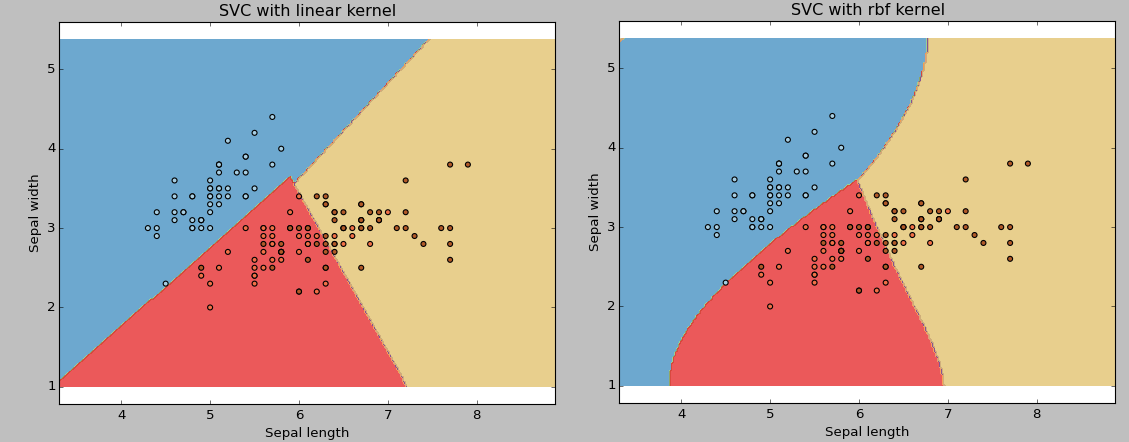
- Polynomial Kernel
- RBF Kernel
- Gamma
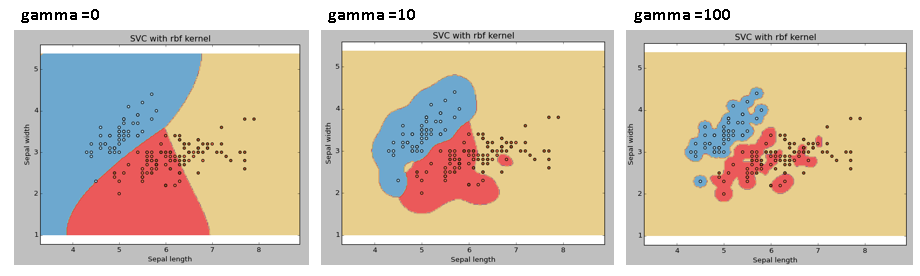
للبيانات غير الخطية
- Large values of gamma tend to overfit.
- Small values of gamma tend to underfit.
- Degree
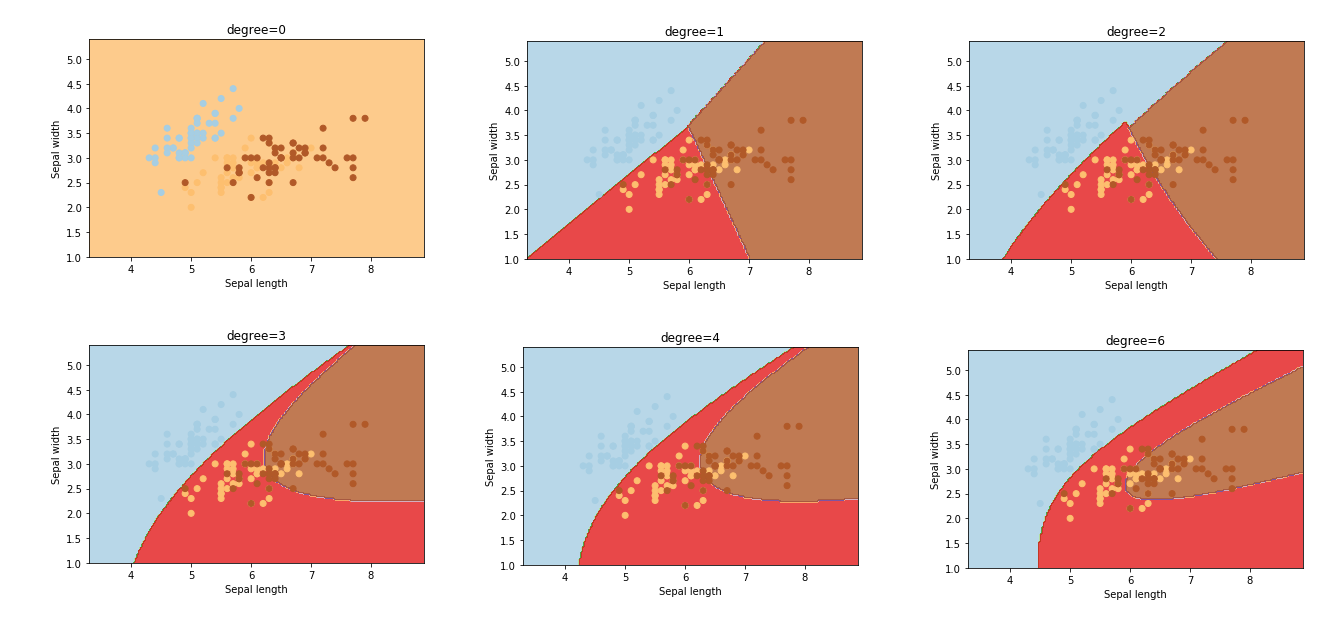
تستخدم فقط في Polynomial Kernel.
مثال بايثون
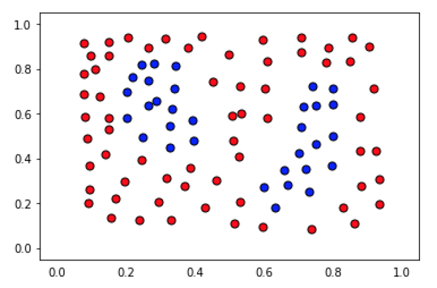
قبل تشغيل المودل
from sklearn.svm import SVC
from sklearn.metrics import accuracy_score
import pandas as pd
import numpy as np
data = np.asarray(pd.read_csv('data.csv', header=None))
X = data[:,0:2]
y = data[:,2]
model = SVC(kernel='rbf', gamma=10, C=7)
model.fit(X, y)
y_pred = model.predict(X)
acc = accuracy_score(y, y_pred)
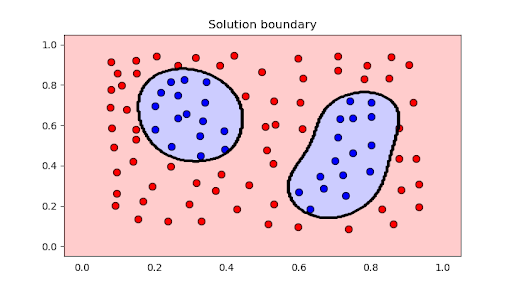
بعد التشغيل
العودة إلى ملخص كورس علم البيانات - 3 - الإنتقال إلى ملخص كورس علم البيانات - 5
كُتب في 17/03/2019