
📝 ملخص كورس علم البيانات - 5
هذا المخلص سيكون عن Ensemble Methods وكيف تُحسن من نتائج المودل لدينا.
الفصل الأول - التعلم الموجَّه Supervised Learning
الدرس السابع - طريقة تجميعية Ensemble Methods
جمع أكثر من مودل مع بعضها البعض لتكوين مودل جديد أفضل منها جميعها. وتوجد طريقتين:
- Bagging: فكرتها ببساطة هي تجميع عدد من التوقعات المختلفة عن البيانات لدينا وإيجاد أفضل النتائج بعد جمعها. الصورة التالية توضح الفكرة ببساطة. 1
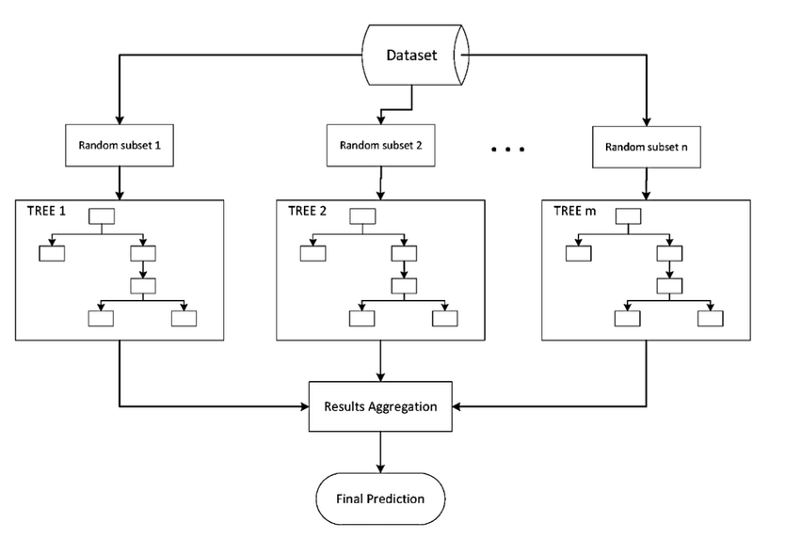
وتستخدم إذا أردنا التقليل من التباين Variance. - Boosting: بنفس الطريقة السابقة، ولكن فيه نأخذ النتائج التي توقعت بشكل خاطئ ونعيد تدريبها. واشهر الخوارزميات التي تقوم بذلك هي AdaBoost. 2
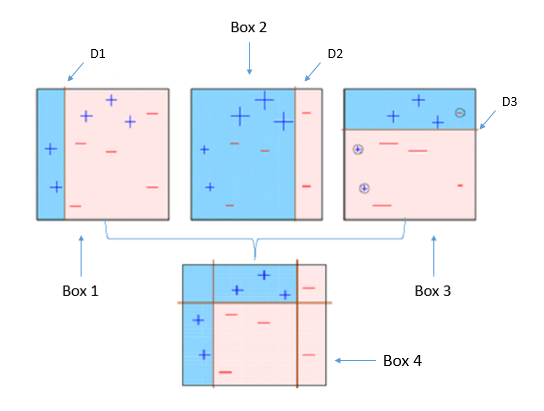
كما يتضح بالصوره، من اليسار إلى اليمين، ركزنا على النتائج الخاطئة في الأولى في الخطوة الثانية، وكذلك في الثالثة، إلى ان وصلنا إلى مودل مناسب.
طريقتين لإيجاد مودل مناسب
عند إنشاء اي مودل وتجربته، يجب علينا فهم نتائج التوقعات الخاطئة Prediction Errors، ولإيجاد أفضل مودل يجب أن نتحقق من التالي:
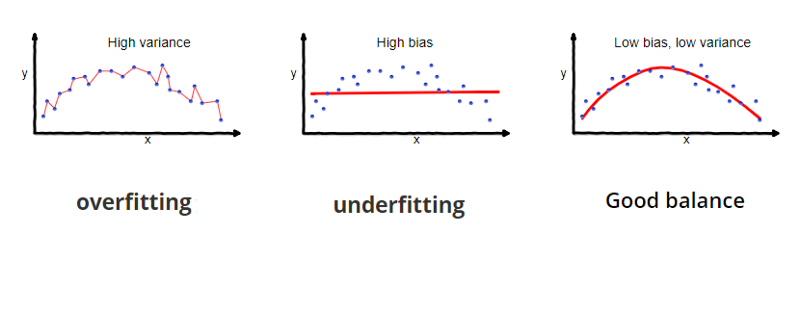
- Bias الإنحياز: وتعني مدى بعد النتائج من الأجوبة او التوقعات الصحيحه.
- Variance التباين: عندما يكون المودل يؤدي جيداً مع البيانات التي لدينا فقط، وإذا اعطي بيانات جديدة، لا يؤدي بنفس الجودة التي يأديها على البيانات الأصليه.
خوارزمية الغابة العشوائية Random Forests
وتعمل هذه الخوارزمية بنفس فكرة خوارزمية شجرة القرار، وعملها سيكون كالتالي:
- تأخذ عدد من المتغيرات Features وتكون شجرة قرار منها.
- تكرر نفس العملية بمتغيرات مختلفه (ممكن ان يتكرر متغير في أكثر من شجره).
- بعد الإنتهاء، نقوم بالإختبار، الإختبار يتم على كُل شجرة كوناها في الخطوتين الأولى ونُظهر نتائجها.
- ومن تلك النتائج نختار الأفضل.
Hyperparameters المتغيرات لخوارزمية AdaBoost
- base_estimator: الخوارزمية التي نريد ان يتعلم منها، الخوارزمية الإفتراضية هي شجرة القرار Decision Tree.
- n_estimators: عدد مرات تكرار التدريب للنتائج الخاطئة.
مثال بايثون
ملاحظة: المثال بدون بيانات حقيقه، ولكن لنفترض اننا قسمنا البيانات لبيانات تدريب وإختبار وبيانات التدريب لدينا هي training_data ونتائجها y_train, وبيانات الإختبار هي testing_data
from sklearn.ensemble import AdaBoostClassifier
from sklearn.ensemble import BaggingClassifier
from sklearn.ensemble import RandomForestClassifier
bagging = BaggingClassifier(n_estimators=200)
random_forest = RandomForestClassifier(n_estimators=200)
adaboost = AdaBoostClassifier(n_estimators=300, learning_rate=0.2)
modelBagging = bagging.fit(training_data, y_train)
modelRandomForest = random_forst.fit(training_data, y_train)
modelAdaBoost = adaboost.fit(training_data, y_train)
predBagging = modelBagging.predict(testing_data)
predRandomFores = modelRandomForest.predict(testing_data)
predAdaBoos = modelAdaBoost.predict(testing_data)
العودة إلى ملخص كورس علم البيانات - 4 - الإنتقال إلى ملخص كورس علم البيانات - 6
كُتب في 19/03/2019