
📝 ملخص كورس علم البيانات - 6
المخلص يغطي طريقة تقييم النموذج، مدى كفائته، قياس أداءة والطرق لتحسينه.
الفصل الأول - التعلم الموجَّه Supervised Learning
الدرس الثامن - مقاييس تقييم النموذج Model Evaluation Metrics
- Train_test_split: استخدمت طريقة في الملخص الثاني لتقسيم البيانات لقسمين، قسم للتدريب وقسم للإختبار، وتم إستعمال train_test_split لذلك، هذه أحدى طرق تقييم المودل. ولديها بعض الخصائص (متغيرات):
- test_size: حجم البيانات المراد إختبارها، اذا اعطيت 0.5، فانها تأخذ 50% من البيانات.
- train_size: نفس تعريف test_size ولكن لبيانات التدريب، ولا يحتاج لتعريفة وإعطائة قيمة اذا تم تعريف وإعطاء قيمة لحجم البيانات المراد إختبارها.
- random_state: عند تخصيص هذا المتغير، لا تتغير لدينا البيانات المفصولة في كل مرة نشغل فيها المودل. عندما لا يحدد، في كل مرة نشغل فيها المودل، تتغير لنا البيانات المفصلة لدينا بين البيانات التي تدرب والتي تُختَبر.
مثال بايثون
from sklearn.tree import DecisionTreeClassifier
from sklearn.metrics import accuracy_score
from sklearn.cross_validation import train_test_split
import pandas as pd
import numpy as np
data = np.asarray(pd.read_csv('data.csv', header=None))
X = data[:,0:2]
y = data[:,2]
# Test size is 25%
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.25, random_state=42)
model = DecisionTreeClassifier()
model.fit(X_train, y_train)
y_pred = model.predict(y_test)
acc = accuracy_score(y_train, y_pred)
قياسات التصنيف Classification Metrics
-
Confusion Matrix: جدول يبين أداء المودل، ويكون كالتالي:
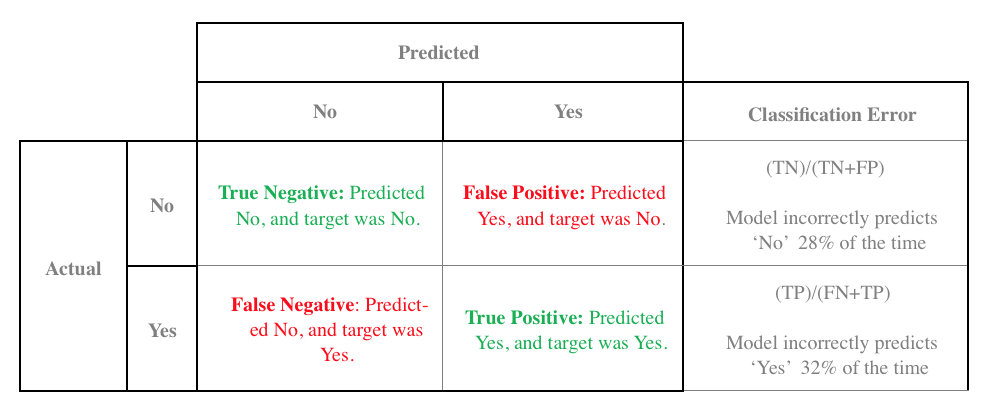
اللون الأخضر في الجدول يعني البيانات التي تم توقعها وكانت نتائجها صحيحه، اللون الأحمر يعني نتائج كان توقعها خاطئ. -
Accuracy: سبق ان تحدثت عنها في الملخص الثالث، وهو يحدد عدد المرات التي كانت إجابة المُصنف (Classifier) صحيحه. وطريقة حسابه هي تابعه لل Confusion Matrix، وطريقة حسابه كالتالي:
[True Positives + True Negaitve/(Total Data)] -
Precision: سبق ان تحدثت عنها في الملخص الثالث، وقلنا انه يحدد نسبة مدى دقة المُصنف في توقعاته الصحيحه.
[True Positives/(True Positives + False Positives)] -
Recall(sensitivity): أيضاً سبق ان تحدثت عنها في الملخص الثالث، وتقوم بحساب البيانات التي توقعناها أنها صحيحه من بين جميع البيانات التي توقعنا انها صحيحه.
[True Positives/(True Positives + False Negatives)] -
F1 Score: وأيضاً سبق ان تحدثت عنها في الملخص الثالث، وهي النتيجة الكاملة لكفائة ودقة المودل.
F1 Scode = 2 * ( (Precision * Recall) / (Precision + Recall) )
ويفضل إستخدامة بدل Percision و Recall كونهما أحياناً في بعض البيانات يقدما نتائج خاطئة ولا تدل فعلاً عن جودة المودل. 1 2 -
F-beta: معلومات مفصلة عنها هنا، ولكن ببساطة إذا اردنا ان نكرز أكثر على Precision، نعطيها رقماً بين 0 و 1، وإذا أردناها ان تركز على Recall أكثر، فنعطيها رقماً أعلى من 1.
-
ROC Curve: ويقوم هذا المقياس على تقييم مدى قدرة المودل على التوقع. 3
قياسات الإنحدار الخطي Regression Metrics
سبق أن شرحت هذه النقاط في الملخص الأول وهي:
- Mean Absolute Error
- Mean Squared Error
اسئلة وأجوبة
- When can you use the model
- decision trees? both regression and classification
- random forest? both regression and classification
- adaptive boosting? both regression and classification
- logistic regression? classification
- linear regression? regression
- Which metric we should use if we want to:
- We have imbalanced classes, which metric do we definitely not want to use? accuracy, naive-bayes
- We really want to make sure the positive cases are all caught even if that means we identify some negatives as positives? recall, svm
- When we identify something as positive, we want to be sure it is truly positive? precision, ada-boost
- We care equally about identifying positive and negative cases? f1-score, random-forest
- Which model for each metric:
- precision? classification
- recall? classification
- accuracy? classification
- r2_score? regression
- mean_squared_error? regression
- area_under_curve? classification
- mean_absolute_area? regression
الفصل الأول - التعلم الموجَّه Supervised Learning
الدرس التاسع - التدريب والضبط Training and Tuning
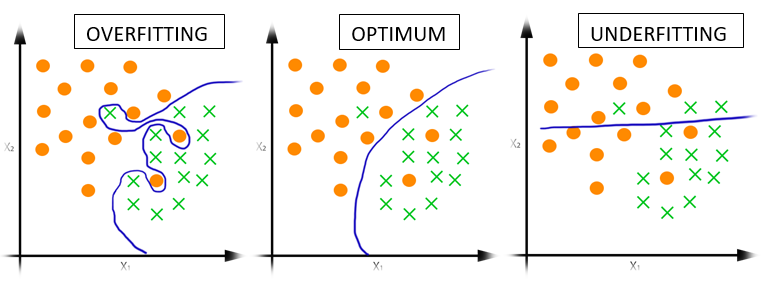
- Underfitting فرط التعميم: عندنا لا ندرب المودل بشكل جيد وتظهر نتائج سيئة عند قياس اداءة. (High Bias)
- Overfitting فرط التخصيص: عندما يكون المودل لدينا مدرب بشكل كامل ودقيق جداً، ويظهر أداة الفعلي عندما يعطى بيانات جديدة فيكون غير قادر على أداء نفس الأداء الذي قام به مع البيانات التي تدرب عليها. (High Variance)
التحقق المتقاطع Cross Validation
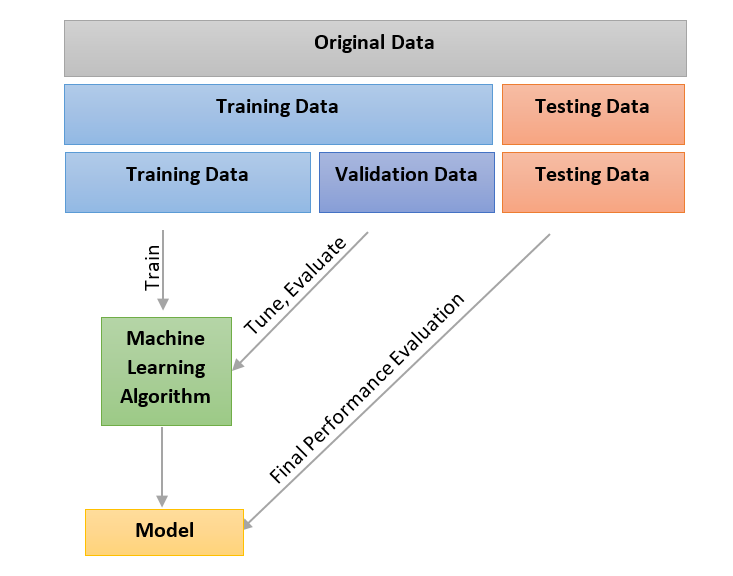
وظيفتها كالتالي، تقسيم البيانات إلى ثلاث اقسام، القسم الأول لتدريب المودل، القسم الثاني لتعديل وضبط خصائص المودل، والقسم الأخير للإختبار. 6 7
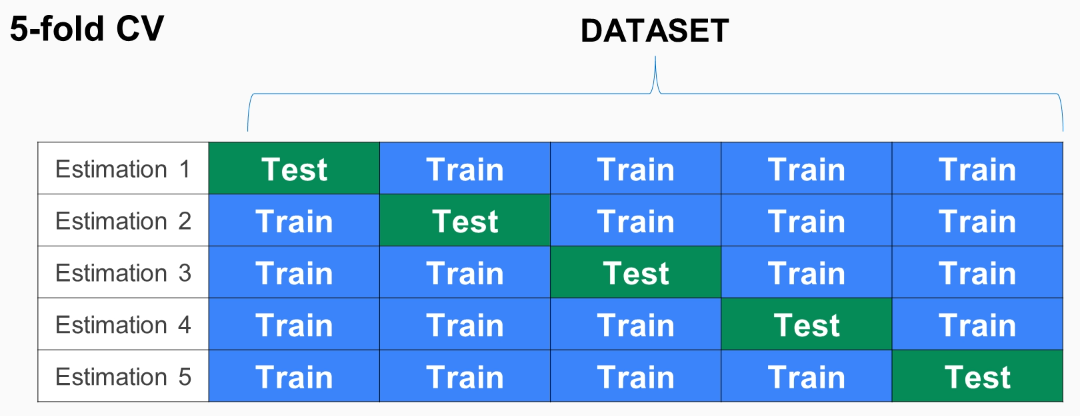
وطريقة فعل ذلك عبر خاصية K-Fold، تقوم بتقسيم البيانات إلى عدد معين نحددة لها، بعد تقسيمها نختبر المودل على كل واحده، وفي كل مره نقوم بتغير البيانات التي ندربها والبيانات التي نختبرها. 8 9
مثال كود بايثون
from sklearn.model_selection import KFold
X = np.array([[1, 2, 7], [3, 4, 6], [1, 2, 0], [3, 4, 9]])
y = np.array([1, 2, 3, 4])
kf = KFold(n_splits=2, shuffle=True)
kf.get_n_splits(X)
# returns 2
# to check that it is different each iteration
for train_index, test_index in kf.split(X):
print("TRAIN:", train_index, "TEST:", test_index)
X_train, X_test = X[train_index], X[test_index]
y_train, y_test = y[train_index], y[test_index]
Learning Curves
طريقة لتحديد المودل ما إذا كان Overfitting، Underfitting، او مناسب. عن طريق رسم بياني، مثال: 10 11
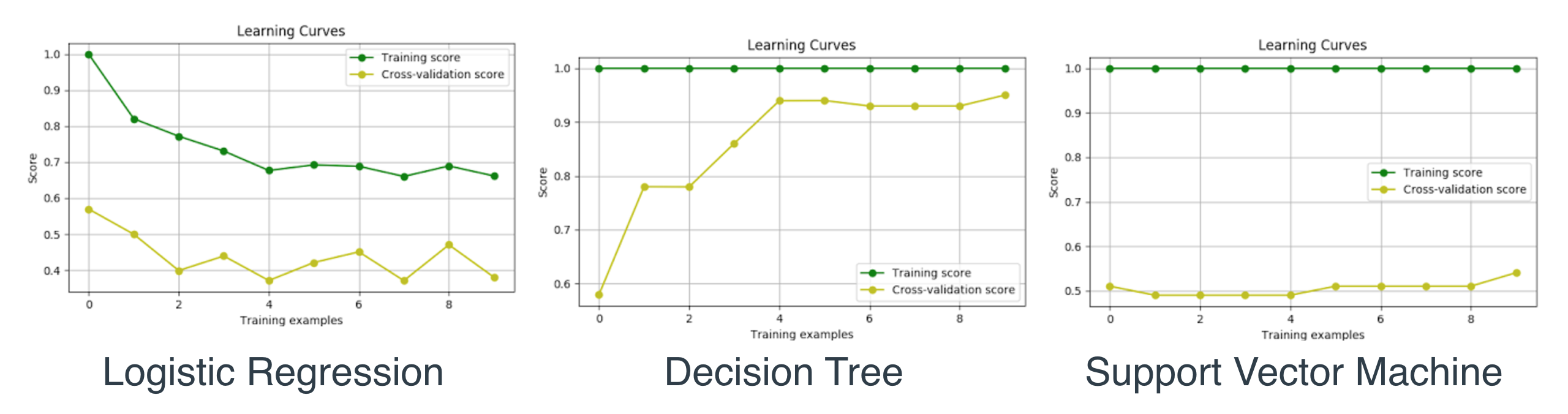
الخط الأخضر هنا هي بيانات التدريب، الخط الأصفر هي بيانات الإختبار. وكما يتضح أن افضلها هي الوسطى كون الخطين يقتربان أكثر فأكثر من بعضهما البعض. الرسم البياني على اليسار هو مثال لـUnderfitting وعلى اليمين مثال لـOverfitting
train_sizes, train_scores, test_scores = learning_curve(
estimator, X, y, cv=None, n_jobs=1, train_sizes=np.linspace(.1, 1.0, num_trainings))
والمتغيرات فيه هي:
- estimator: وهي الخوارزمية التي استخدمانها لإنشاء المودل. مثلاً LogisticRegression.
- X, y: وهي البيانات.
- train_sizes: حجم كل جزء من البيانات التي ستستخدم في الرسم البياني.
- train_scores: درجة بيانات التدريب كل جزء من البيانات على الخوارزمية التي نختبرها فيها.
- test_scores: درجة بيانات الإختبار كل جزء من البيانات على الخوارزمية التي نختبرها فيها.
Grid Search
شرحنا في أكثر من خوارزمية سابقة بعض المتغيرات Hyperparameters، وظيفة Grid Search هي إيجاد أفضل تكوينة من المتغيرات.
مثال بايثون 12 13
from sklearn.metrics import make_scorer
from sklearn.model_selection import GridSearchCV
clf = DecisionTreeClassifier(random_state=42)
parameters = {'max_depth':[2,3,4,5], 'min_samples_leaf':[5,10,15], 'min_samples_split':[5,10,15]}
scorer = make_scorer(f1_score)
grid_obj = GridSearchCV(clf, parameters, scorer)
grid_fit = grid_obj.fit(X_train, y_train)
best_clf = grid_fit.best_estimator_
والنتيجة ستكون بهذا الشكل:
DecisionTreeClassifier(class_weight=None, criterion='gini', max_depth=4,
max_features=None, max_leaf_nodes=None,
min_impurity_decrease=0.0, min_impurity_split=None,
min_samples_leaf=2, min_samples_split=2,
min_weight_fraction_leaf=0.0, presort=False, random_state=42,
splitter='best')
أي خوارزمية أختار؟
عند مواجهة أي مشكلة يجب عليك تجربة أكثر من خوارزمية وعرض النتائج لتحديد الأفضل بينهم، الصور التالية تعطي اقتراحات متى وأي خوارزمية تختار: 14 15
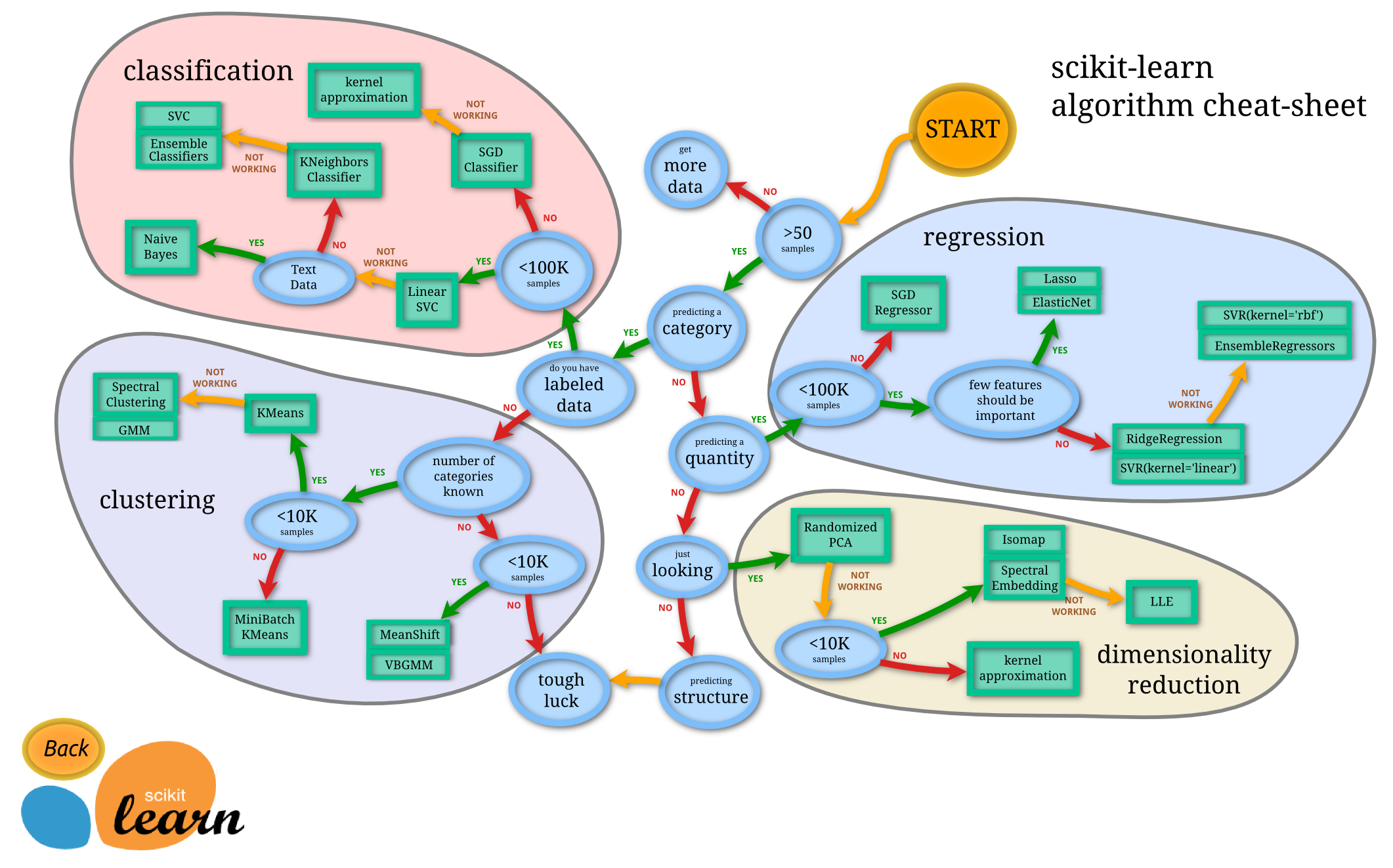
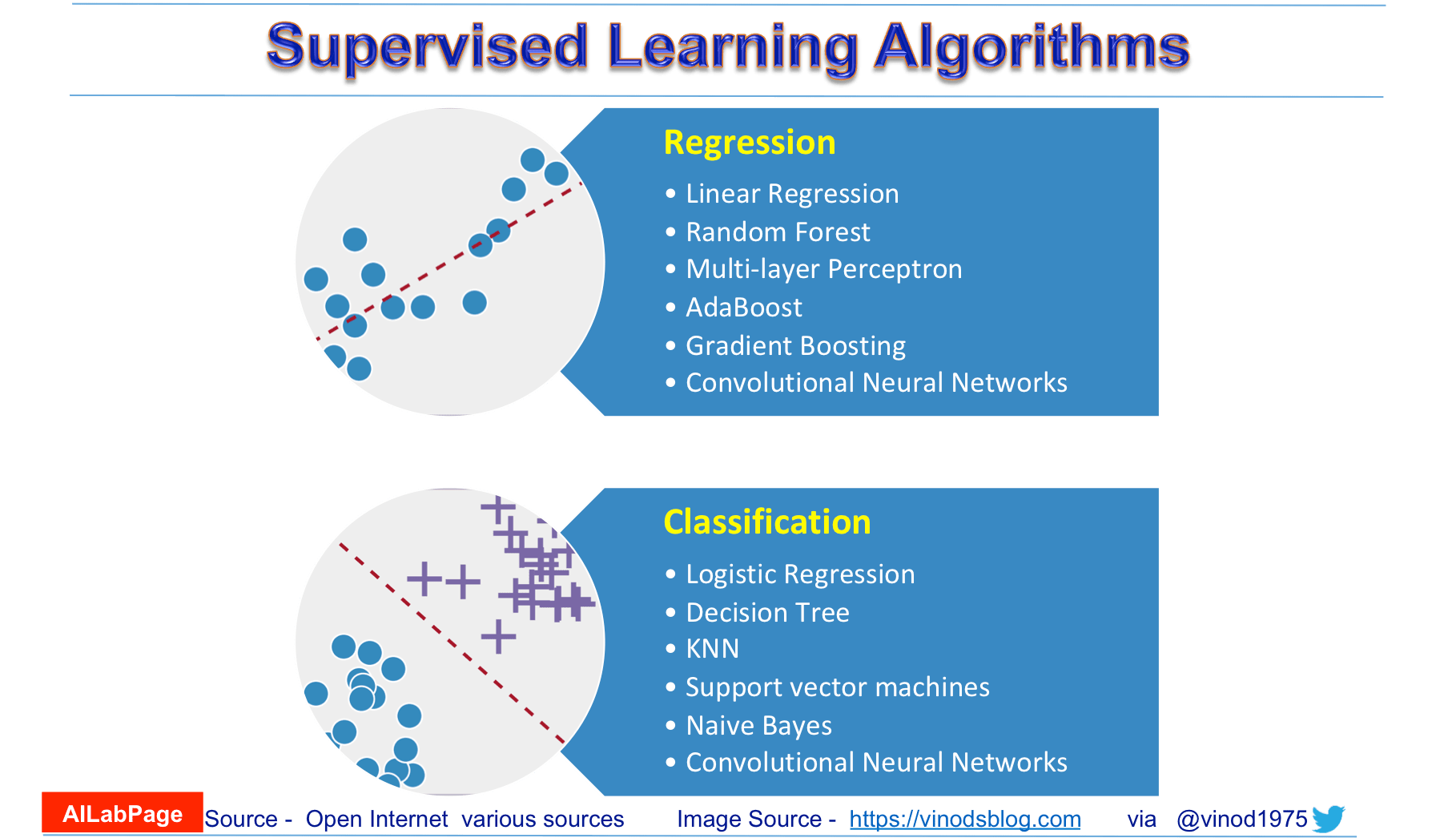
العودة إلى ملخص كورس علم البيانات - 5 - الإنتقال إلى ملخص كورس علم البيانات - 7