مبادئ وتقنيات علم البيانات
الفصل الأول: دورة حياة علم البيانات
فهرس الفصل:
مقدمة
في علم البيانات، نستخدم بيانات عديدة ومتنوعة لاتخاذ قراراتنا. في هذا الكتاب سنشرح مبادئ وتقنيات علم البيانات من الجانب الحسابي والتفكير الاستدلالي. وتشمل الخطوات التالية:
- تشكيل السؤال أو المشكلة.
- إيجاد وتنظيف البيانات.
- التحليل الاستكشافي للبيانات.
- استخدام التوقع والاستدلال لإيجاد النتائج.
ومن المتوقع أن تظهر مزيد من الأسئلة والمشاكل بعد آخر خطوة، في ذلك الوقت يمكننا إعادة الخطوات مرة أخرى لاكتشاف أي خصائص جديدة في مشكلتنا. هذا التكرار الإيجابي في عملنا يسمى دورة حياة علم البيانات.
إذا كانت دورة حياة علم البيانات سهلة، لما احتجنا كتباً لشرحها. لحسن حظنا، كل خطوة لديها عدد مختلف من التحديات التي تكشف لنا أفكار جديدة تكون هي أساساً لاتخاذ قرارات مدروسة باستخدام البيانات.
طلاب داتا 100
دورة حياة علم البيانات تتكون من الخطوات التالية:
1- تشكيل السؤال أو المشكلة:
- ما الذي نريد معرفته، أو ما هي المشكلة التي نريد حلها؟
- ما هي الفرضيات؟
- ما هي مقاييس نجاحنا؟
2- إيجاد وتنظيف البيانات:
- ما هي البيانات المتوفرة لدينا وما هي التي نبحث عنها؟
- كيف سنتمكن من جمع المزيد من البيانات؟
- كيف نرتب البيانات لنبدأ التحليل؟
3- التحليل الاستكشافي للبيانات:
- هل لدينا بيانات ذات علاقة بمشكلتنا؟
- هل تحتوي البيانات على تحيزات، بيانات شاذة، أو مشاكل أخرى؟
- كيف نحول البيانات لتساعدنا على القيام بتحليل فعال؟
4- التوقع والاستدلال:
- ماذا تخبرنا البيانات؟
- هل أجابت على السؤال أو حلت المشكلة؟
- ما مدى قوة نتائجنا؟
سنقوم الآن بتجربة هذه الخطوات على قاعدة بيانات الأسماء الأولى لطلاب داتا 100 من الفصول السابقة. في هذا الفصل، قمنا بالمرور بشكل سريع على الخطوات لإعطاء القارئ معلومات عن الدورة الكاملة. في فصول لاحقة، سنتحدث بشكل مفصل ونشرح كل خطوة.
تشكيل السؤال أو المشكلة
نريد أن نعرف ما إذا كانت الأسماء الأولى للطلاب تقدم لنا معلومات إضافية عنهم. رغم أن السؤال يبدو غامضاً نوعاً ما، لكنه كافياً لجعلنا نعمل على البيانات المتوفرة لدينا ويمكننا التعديل في السؤال أثناء عملنا لنجعله أكثر دقة.
إيجاد وتنظيف البيانات
لنبدأ بأخذ نظرة سريعة عن البيانات المتوفرة لدينا، البيانات هي قائمة لأسماء الطلاب الأولى للذين سبق أن درسوا مادة داتا 100. لا تقلق إن لم تفهم الكود البرمجي؛ سنشرحه ونشرح المكتبات المستخدمة لاحقاً. حالياً، ركز على الخطوات والرسوم البيانية:
لتحميل بيانات اسماء الطلاب اضغط هنا.
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
students = pd.read_csv('roster.csv')
students
| Name | Role | |
|---|---|---|
| Keeley | Student | 0 |
| John | Student | 1 |
| BRYAN | Student | 2 |
| … | … | … |
| Ernesto | Waitlist Student | 276 |
| Athan | Waitlist Student | 277 |
| Michael | Waitlist Student | 278 |
279 rows × 2 columns
يمكن أن نلاحظ بشكل سريع وجود بعض المشاكل في بياناتنا. مثلاً، أحد الطلاب كُتب اسمه بالأحرف الكبيرة بشكل كامل BRYAN، بالإضافة إلى أن معنى العمود Role لا يبدو واضحاً. نلاحظ أيضاً أن الجدول يحتوي على عامودين و 279 سطراً.
في هذه المادة، سنتعلم كيفية اكتشاف الأخطاء في بياناتنا وتصحيحها. الاختلاف في الحروف الكبيرة في الاسم Bryan سيجعل البرنامج يتوقع أن BRYAN يختلف عن Bryan ولكن في الحقيقة هما نفس الشخص. لذا سنحول جميع الأسماء إلى حروف صغيرة:
students['Name'] = students['Name'].str.lower()
students
| Name | Role | |
|---|---|---|
| keeley | Student | 0 |
| john | Student | 1 |
| bryan | Student | 2 |
| … | … | … |
| ernesto | Waitlist Student | 276 |
| athan | Waitlist Student | 277 |
| michael | Waitlist Student | 278 |
279 rows × 2 columns
الآن، وبما أن البيانات لدينا بدأت تظهر بشكل مقبول، يمكننا الانتقال للخطوة التالية.
التحليل الاستكشافي للبيانات
التحليل الاستكشافي للبيانات أو Exploratory Data Analysis واختصارها EDA يطلق على الخطوات التي نتبعها لمعرفة صفات البيانات لعمل تحليلات لها لاحقاً. لنستعرض بيانات الطلاب:
students
| Name | Role | |
|---|---|---|
| keeley | Student | 0 |
| john | Student | 1 |
| bryan | Student | 2 |
| … | … | … |
| ernesto | Waitlist Student | 276 |
| athan | Waitlist Student | 277 |
| michael | Waitlist Student | 278 |
279 rows × 2 columns
الآن لدينا بعض الأسئلة، كم عدد الطلاب؟ ماذا يعني عمود Role؟ نقوم بخطوة التحليل الاستكشافي للبيانات للإجابة على مثل هذه الأسئلة.
كم عدد الطلاب؟
print("There are", len(students), "students on the roster.")
There are 279 students on the roster.
عدد الطلاب لدينا هو 279 طالباً. السؤال التالي دائماً يكون: هل تحتوي البيانات على كامل الطلاب؟ في حالتنا، الجدول يحتوي على جميع الطلاب الذين درسوا مادة داتا 100 في فصلٍ دراسيٍّ واحد.
ماذا يعني عمود Role؟
لنستكشف البيانات التي في هذا العمود لنعرف معناه:
students['Role'].value_counts().to_frame()
| Role | |
|---|---|
| 237 | Student |
| 42 | Waitlist Student |
يمكن أن نرى في الجدول السابق أن البيانات لا تحتوي فقط على الطلاب الذين درسوا المادة Student، بل أيضاً على الطلاب الموجودين في قائمة الانتظار Waitlist Student. إذاً، العمود Role يخبرنا إذا كان الطالب التحق بالمادة أم لا.
ماذا عن عمود Name؟ كيف يمكننا استكشافه؟
في هذه المادة سنتعامل مع عدد كبير من أنواع البيانات. الرقمية، النوعية والنصية. كل نوع له أساليبه وأدواته الخاصة للاستكشاف.
طريقة سريعة لفهم عمود الأسماء Name هي بمعرفة عدد الأحرف في كل اسم:
sns.distplot(students['Name'].str.len(),
rug=True,
bins=np.arange(12),
axlabel="Number of Characters")
plt.xlim(0, 12)
plt.xticks(np.arange(12))
plt.ylabel('Proportion per character');
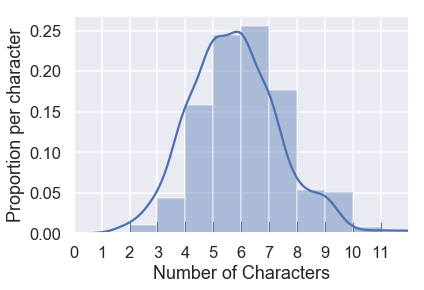
الرسم البياني السابق يخبرنا أن أكثر الأسماء يبلغ طولها بين 4 إلى 8 أحرف. هذا يساعدنا على معرفة ما إذا كانت بياناتنا معقولة أم لا. إذا كان هناك الكثير من الأسماء ذات حرف واحد، فيكون ذلك سبب مناسب لإعادة استكشاف البيانات.
رغم أن البيانات تبدو واضحة وبسيطة، سنعرف لاحقاً كيف أن الاسم الأول فقط قد يخبرنا الكثير عن مجموعة الطلاب لدينا.
ماذا بداخل عمود الاسم؟
حتى الآن، وجهنا سؤال عام: “هل يخبرنا الاسم الأول للطالب أي شيء عن المادة؟”
قمنا بتنظيف البيانات بتحويلها جميعها لأحرف صغيرة. أثناء التحليل الاستكشافي للبيانات لاحظنا أن لدينا حوالي 270 طالباً منهم من درس المادة ومنهم من على قائمة الانتظار. وأكثر الأسماء بين 4 إلى 8 أحرف.
ماذا يمكننا معرفته عن طلاب المادة من أسمائهم؟ لنأخذ اسماً واحداً منها:
students['Name'][5]
'jerry'
من هذا الاسم، يمكننا القول أن صاحب الاسم ذكر. ويمكننا أيضاً توقع عمر الطالب. على سبيل المثال، إذا عرفنا أن اسم Jerry مشهور من بين أسماء الأطفال الذين ولدو في عام 1998، يمكننا التوقع إن عمر الطالب في العشرينيات.
التفكير بهذه الطريقة أوصلنا إلى سؤالين:
- هل تخبرنا أسماء الطلاب عن توزيع الذكور والإناث؟
- هل تخبرنا أسماء الطلاب عن توزيع الأعمار؟
للإجابة على هذه الأسئلة، سنحتاج بيانات تربط بين الأسماء مع الجنس والسنوات. مؤسسة الضمان الاجتماعي الأمريكية لديها مثل هذه البيانات ومتوفرة على الإنترنت على الرابط.
سنبدأ أولاً بتحميل البيانات من الموقع ثم نقلها إلى بايثون. مرة أخرى، لا تقلق إذا لم تفهم الكود البرمجي في هذا الفصل، فقط ركز على فهم الخطوات بشكل عام:
import urllib.request
import os.path
data_url = "https://www.ssa.gov/oact/babynames/names.zip"
local_filename = "babynames.zip"
if not os.path.exists(local_filename): # اذا توفرت البيانات، لا تحملها مرة أخرى
with urllib.request.urlopen(data_url) as resp, open(local_filename, 'wb') as f:
f.write(resp.read())
import zipfile
babynames = []
with zipfile.ZipFile(local_filename, "r") as zf:
data_files = [f for f in zf.filelist if f.filename[-3:] == "txt"]
def extract_year_from_filename(fn):
return int(fn[3:7])
for f in data_files:
year = extract_year_from_filename(f.filename)
with zf.open(f) as fp:
df = pd.read_csv(fp, names=["Name", "Sex", "Count"])
df["Year"] = year
babynames.append(df)
babynames = pd.concat(babynames)
babynames
| Year | Count | Sex | Name | |
|---|---|---|---|---|
| 1884 | 9217 | F | Mary | 0 |
| 1884 | 3860 | F | Anna | 1 |
| 1884 | 2587 | F | Emma | 2 |
| … | … | … | ||
| 1883 | 5 | M | Verna | 2081 |
| 1883 | 5 | M | Winnie | 2082 |
| 1883 | 5 | M | Winthrop | 2083 |
1891894 rows × 4 columns
البيانات تحتوي على الأسماء، جنس الطفل، عدد الأطفال بهذا الاسم وسنة ميلاد كل طفل. للتأكيد، لنقرأ ما كتبه مكتب الضمان الاجتماعي في شرحهم للبيانات على الرابط.
جميع الأسماء أتت من بطاقات التقديم للضمان الاجتماعي لجميع الولادات التي كانت في الولايات المتحدة بعد عام 1879. ملاحظة: الكثير ممن ولدوا قبل 1937 لم يقوموا بالتقديم للحصول على البطاقة، لذلك أسماؤهم ليست ضمن البيانات. الآخرين الذين قاموا بتقديم طلباتهم، سجلاتنا لا تُظهر أماكن ولاداتهم، لذلك أسماؤهم أيضاً لم تضاف إلى البيانات. هذه عينة كاملة من البيانات لدينا حتى تاريخ مارس 2017.
نبدأ أولاً بعرض عدد المواليد الذكور والإناث كل سنة:
pivot_year_name_count = pd.pivot_table(
babynames, index='Year', columns='Sex',
values='Count', aggfunc=np.sum)
pink_blue = ["#E188DB", "#334FFF"]
with sns.color_palette(sns.color_palette(pink_blue)):
pivot_year_name_count.plot(marker=".")
plt.title("Registered Names vs Year Stratified by Sex")
plt.ylabel('Names Registered that Year')
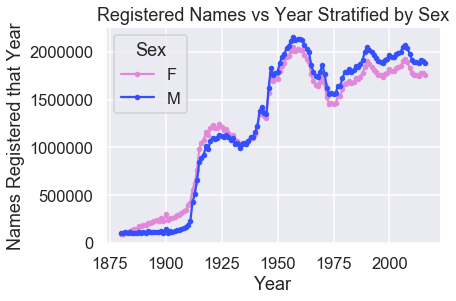
الزيادة المفاجئة لعدد المواليد في عام 1920 تبدو مشبوهة، ولكن في الاقتباس السابق تم توضيح السبب:
ملاحظة: الكثير ممن ولدوا قبل 1937 لم يقوموا بالتقديم للحصول على البطاقة، لذلك أسماؤهم ليست ضمن البيانات. الآخرين الذين قاموا بتقديم طلباتهم، سجلاتنا لا تُظهر أماكن ولاداتهم، لذلك أسماؤهم أيضاً لم تضاف إلى البيانات.
يمكن ملاحظة فترة الإنجاب المتزايدة أو ما تسمى ب Baby boomers والتي كانت في الفترة بين 1946 حتى 1964، لقراءة المزيد عن هذا الموضوع قم بزيارة الرابط.
معرفة الجنس من الاسم
لنستخدم بيانات الأطفال السابقة لمعرفة عدد الذكور والإناث. كما فعلنا سابقاً، نبدأ أولاً بتصغير جميع أحرف الأسماء في بيانات الأطفال:
babynames['Name'] = babynames['Name'].str.lower()
babynames
| Year | Count | Sex | Name | |
|---|---|---|---|---|
| 1884 | 9217 | F | mary | 0 |
| 1884 | 3860 | F | anna | 1 |
| 1884 | 2587 | F | emma | 2 |
| … | … | … | ||
| 1883 | 5 | M | verna | 2081 |
| 1883 | 5 | M | winnie | 2082 |
| 1883 | 5 | M | winthrop | 2083 |
2084 rows × 4 columns
ثم نجمع عدد المواليد لكل اسم ونوع المولود:
sex_counts = pd.pivot_table(babynames, index='Name', columns='Sex',
values='Count', aggfunc='sum',
fill_value=0., margins=True)
sex_counts
| All | M | F | Sex |
|---|---|---|---|
| Name | |||
| 96 | 96 | 0 | aaban |
| 35 | 0 | 35 | aabha |
| 10 | 10 | 0 | aabid |
| … | … | … | |
| 6 | 6 | 0 | zyyon |
| 5 | 5 | 0 | zzyzx |
| 344533897 | 173894326 | 170639571 | All |
96175 rows × 3 columns
لتحديد ما إذا كان الاسم أكثر شيوعاً للأطفال الذكور أم الإناث، يمكننا حساب نسبة تكرار الاسم لدى أحد الجنسين:
prop_female = sex_counts['F'] / sex_counts['All']
sex_counts['prop_female'] = prop_female
sex_counts
| prop_female | All | M | F | Sex |
|---|---|---|---|---|
| Name | ||||
| 0.0 | 96 | 96 | 0 | aaban |
| 1.0 | 35 | 0 | 35 | aabha |
| 0.0 | 10 | 10 | 0 | aabid |
| … | … | … | ||
| 0.0 | 6 | 6 | 0 | zyyon |
| 0.0 | 5 | 5 | 0 | zzyzx |
| 0.5 | 344533897 | 173894326 | 170639571 | All |
96175 rows × 4 columns
يمكننا تعريف دالة لتبحث لنا عمّا إذا كان الاسم ذكراً أو أنثى باستخدام النسبة السابقة:
def sex_from_name(name):
if name in sex_counts.index:
prop = sex_counts.loc[name, 'prop_female']
return 'F' if prop > 0.5 else 'M'
else:
return 'Name not in dataset'
students['sex'] = students['Name'].apply(sex_from_name)
sex_from_name('sam')
'M'
باستخدام الكود البرمجي السابق يمكنك تجربة أي اسم ومعرفة ما إذا كانت نسبة تسميته كذكر أعلى من نسبة تسميته كأنثى.
الآن لنعود إلى بيانات الطلاب ونضيف عليها ما إذا كان الطالب ذكراً أو أنثى:
| Sex | Name | Role | |
|---|---|---|---|
| F | keeley | Student | 0 |
| M | john | Student | 1 |
| M | bryan | Student | 2 |
| … | … | … | |
| M | ernesto | Waitlist Student | 276 |
| M | athan | Waitlist Student | 277 |
| M | michael | Waitlist Student | 278 |
279 rows × 4 columns
الآن يمكننا بسهولة معرفة عدد الذكور والإناث بين طلابنا:
students['sex'].value_counts()
M 144
F 92
Name not in dataset 43
Name: Sex, dtype: int64
إيجاد العمر من الاسم
باستخدام نفس الطريقة السابقة يمكننا إيجاد توزيع العمر في فصلنا، بربط كل اسم مع متوسط السنوات الذي تكرر فيها:
def avg_year(group):
return np.average(group['Year'], weights=group['Count'])
avg_years = (
babynames
.groupby('Name')
.apply(avg_year)
.rename('avg_year')
.to_frame()
)
avg_years
| avg_year | |
|---|---|
| Name | |
| 2012.57 | aaban |
| 2013.71 | aabha |
| 2009.50 | aabid |
| … | … |
| 2010.00 | zyyanna |
| 2014.00 | zyyon |
| 2010.00 | zzyzx |
96174 rows × 1 columns
بنفس الطريقة السابقة، يمكن أن نبحث عن أي اسم ومعرفة متوسط سنة الميلاد:
def year_from_name(name):
return (avg_years.loc[name, 'avg_year']
if name in avg_years.index
else None)
students['year'] = students['Name'].apply(year_from_name)
students
| Year | Sex | Name | Role | |
|---|---|---|---|---|
| 1998.15 | F | keeley | Student | 0 |
| 1951.08 | M | john | Student | 1 |
| 1983.57 | M | bryan | Student | 2 |
| … | … | … | ||
| 1981.44 | M | ernesto | Waitlist Student | 276 |
| 2004.40 | M | athan | Waitlist Student | 277 |
| 1971.18 | M | michael | Waitlist Student | 278 |
279 rows × 4 columns
الآن، يمكننا بسهولة عرض توزيع السنوات بين الطلاب:
sns.distplot(students['year'].dropna());
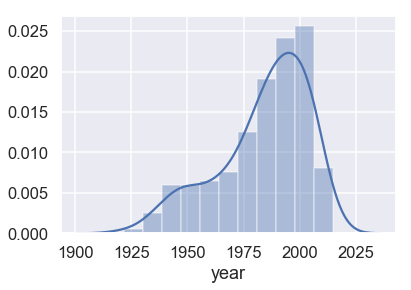
ولعرض متوسط عمود السنة نقوم بالآتي:
students['year'].mean()
1983.846741800525
متوسط الأعمار لدينا هو 35 سنه (2018-1983=35)، تقريباً أكثر بمرتين من العمر المتوقع للطلاب الجامعيين. لماذا تظهر لنا الأعمار مرتفعة بهذا الشكل؟
كعالم بيانات، قد نصل لنتائج لا نتفق معها أو عكس توقعاتنا. التحدي الدائم الذي يواجهنا هو معرفة ما إذا كانت النتائج التي فاجأتنا سببها خطأ في إحدى خطواتنا أو خطأ حقيقي في البيانات. بما أنه لا يوجد هناك طريقة سهلة لضمان نتائج دقيقة، يجب أن يكون لدى عالم البيانات مبادئ وقواعد للتقليل من إيجاد نتائج خاطئة.
في حالتنا، التفسير الوحيد للنتيجة غير المتوقعة التي ظهرت لنا هو أن الأسماء الأكثر شيوعاً تستخدم منذ سنوات عديدة. مثلاً الاسم John يعتبر من الأسماء الأكثر شيوعاً عبر التاريخ بناءً على البيانات التي حصلنا عليها. يمكننا تأكيد ذلك بعرض رسم بياني لعدد الأطفال الذين تم تسميتهم John كل سنة:
names = babynames.set_index('Name').sort_values('Year')
john = names.loc['john']
john[john['Sex'] == 'M'].plot('Year', 'Count')
plt.title('Frequency of "John"');
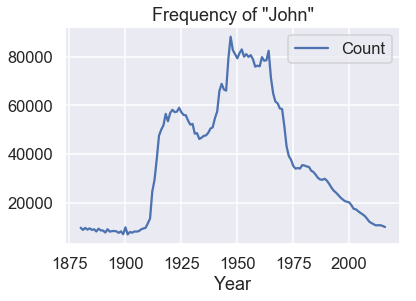
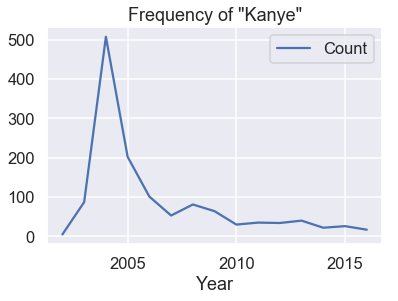
يبدو لنا أن متوسط السنة لا يعطي توقع دقيق لعمر الشخص. ولكن في بعض الحالات، الاسم الأول للشخص يساعدنا على ذلك، على سبيل المثال عند التجربة على اسم Kanye تظهر لنا النتيجة التالية:
names = babynames.set_index('Name').sort_values('Year')
kanye = names.loc['kanye']
kanye[kanye['Sex'] == 'M'].plot('Year', 'Count')
plt.title('Frequency of "Kanye"');
الملخص
في هذا الفصل، قمنا بالمرور بشكل سريع على دورة حياة علم البيانات: تشكيل السؤال أو المشكلة، إيجاد وتنظيف البيانات، التحليل الاستكشافي للبيانات، التوقع والاستدلال. سنشرح بشكل مفصل كل خطوة في الفصول القادمة.
النصف الأول من الكتاب (الفصل 1 حتى 9) سيغطي الثلاث خطوات الأولى من دورة حياة علم البيانات ويركز بشكل كبير على طريقة الحساب وإيجاد النتائج. النصف الثاني (الفصل 10 حتى 18) يستخدم التفكير الحسابي والإحصائي لتغطية مواضيع بناء النماذج، الاستدلال والتوقع.
بشكل عام، يسعى هذا الكتاب لتعريف القارئ على مبادئ وتقنيات علم البيانات.