مبادئ وتقنيات علم البيانات
الفصل الثالث: البيانات المجدولة ومكتبة بانداز
فهرس الفصل:
مقدمة
العمل مع البيانات المجدولة
البيانات المجدولة Tabular data تعتبر من أكثر أشكال البيانات استخداماً. في الفصلين السابقة استخدمنا مكتبة بانداز Pandas للتعامل مع البيانات المجدولة، بانداز تعتبر المكتبة الرائدة في هذا المجال. رغم أن الكتابة في بانداز تبدو صعبة بعض الشيء، لكنها تحسن كثيراً من الأداء وتسهل التعامل مع البيانات المجدولة وتعتبر الأولى في المجال سواء في الأوساط العملية أو الأكاديمية.
من المهم أن تفهم الخطوات الأساسية للتعامل مع البيانات بدلاً من فهم تفاصيل كتابة الأوامر في بانداز. مثلاً، فهم متى تستخدم خاصية الجمع Group by أكثر أهمية من معرفة كيفية كتابة الأمر في بانداز. بما أن هذا الفصل يحتوي على الكثير من الأكواد البرمجية، ننصحك بالتركيز والقراءة أكثر من مرة: مرة لفهم الكود البرمجي، ومرة لفهم متى يجب عمل هذه الأمر.
لأننا سنغطي فقط أهم الأوامر المستخدم في بانداز، يمكنك الرجوع دائماً لشرح المكتبة عندما تقوم بنفسك بتحليل البيانات.
سنبدأ أولاً بالحديث عن أشكال البيانات التي يمكن لبانداز قراءتها. ثم سنتكلم عن أسماء الأعمدة، التقسيمات، التجميع، دالة التطبيق والنصوص في البيانات المجدولة.
هيكلة البيانات
هيكل وشكل البيانات يعتبر مهم لفهم وعرض البيانات. مثلاً، البيانات التي تكون على شكل جداول نعرضها في أعمدة وصفوف. على العكس البيانات الهرمية، كشجرة العائلة، تسمح لكل قيمة أن تحتوي على قيم أخرى بأشكال مختلفة. يوجد الكثير من الطرق لهيكلة وعرض البيانات، في هذا الكتاب سنعمل غالب الوقت على البيانات التي تظهر على شكل جداول.
صيغة ملف البيانات، توضح كيف تم حفظ البيانات على جهاز الكمبيوتر،. مثلاً، ملف comma-separated values (CSV) يحتوي على بيانات يفصل بين كل قيمة والأخرى فاصلة ( , ). في هذا الكتاب سنطبق على عدة أنواع:
- Comma-Separated Values (CSV) و Tab-Separated Values (TSV). هذان النوعان عادةً ما تحتوي على بيانات بشكل جداول. في هذه الملفات كل سطر يمثل صف; ويفصل بين البيانات بعلامة الفاصلة ( , ) أو علامة Tab ( \t ). أول صف في هذه الملفات عادة ما يكون مخصص لأسماء الأعمدة. 📝
- JavaScript Object Format (JSON) نوع آخر يستخدم بكثرة للتواصل بين تطبيقات وخوادم المواقع. ملفات JSON تكون ذات هيكل هرمي وتحتوي على مفاتيح Keys وقيم Values، عندما نريد قيمة معينة نبحث عنها بالمفتاح الخاص فيها، تشبه بشكل كبير القواميس Dictionary في لغة بايثون. 📝
- eXtensible Markup Language (XML) و HyperText Markup Language (HTML) هي صيغ معروفة لحفظ البيانات على الإنترنت. كما في JSON، هذه الملفات هرمية وتتبع طريقة المفاتيح والقيم. 📝
يوجد الكثير من الأدوات للتعامل مع أنواع مختلفة من صيغ الملفات، في هذا الكتاب سنقوم دائما بمعالجة البيانات وتحويلها إلى جداول. لماذا نجرب أنفسنا على هذا الخيار؟ أولاً، الكثير من البحوث قامت بعرض الطرق المناسبة لحفظ ومعالجة الجداول. ثانياً، الجداول تشبه كثيراً المصفوفات لذا استخدامها أسهل بكثير للقيام بالعمليات الرياضية. أخيراً، جداول البيانات هي الأكثر استخداماً.
في بانداز يمكننا استخدام الدالة pd.read_csv لقراءة ملفات CSV و TSV، الملفات الأخرى لها دوال مختلفة، لذا نحتاج أولاً التحقق من نوع صيغة الملف قبل التعامل معه.
أدوات سطر الأوامر
جميع أجهزة الكمبيوتر توفر إمكانية الوصول لـ مترجم شيل Shell Interpreter، مثل sh أو bash. كما في مترجم نصوص بايثون، يسمح المترجم للمستخدم بكتابة الكود البرمجي وعرض نتيجته. مترجم شيل يقوم بعملياته مع الحاسب وملفاته، ولدية لغته الخاصة ودوال وطريقه مختلفة بالكتابة.
نستخدم المصطلح أداة سطر الأوامر command-line interface (CLI) للحديث عن الأوامر التي تستخدم في الشيل. رغم أننا سنتحدث عن القليل من أدوات سطر الأوامر في هذا الفصل، إلا أنه يوجد الكثير من الأدوات التي تسمح لنا بالعديد من العمليات التي يمكن فعلها على الحاسب.
ملاحظة: جميع أدوات سطر الأوامر مخصصة لشيل sh، المترجم الافتراضي على أجهزة ماكنتوش ولينكس. تم استخدام Jupyter والذي يستخدم نفس الأداة. أجهزة ويندوز تستخدم مترجم سطر أوامر آخر وبعض الأوامر المستخدمة في هذا الكتاب قد لا تعمل على ويندوز. 📝
يمكن استخدام أوامر sh على أجهزة ويندوز عن طريق Gitbash.
بما أن أداة جوبتر تستخدم نفس مترجم شيل، فبإمكاننا استخدام الأوامر في خلايا الأداة. إذا أضيفت علامة تعجب ( ! ) قبل الحرف، فإن الأداة تفهم أن هذا الأمر هو أمر لمترجم شيل فيتم إرسال الأمر له. مثلاً الأمر ls يعرض لنا جميع الملفات في المجلد الذي نعمل فيه حالياً:
!ls
babynames.csv pandas_indexes.ipynb
others pandas_intro.ipynb
pandas_apply_strings_plotting.ipynb pandas_structure.ipynb
pandas_grouping_pivoting.ipynb
أدوات ودوال سطر الأوامر مثل ls عادة ما تأخذ متغيرات، تماماً كما تأخذ دوال بايثون متغيرات. في sh، نقوم بوضع المتغيرات بين مسافات، وليس أقواس كما في بايثون. كتابة الأمر ls ثم اسم المجلد يظهر لنا الملفات داخل ذلك المجلد:
!ls others
babies.data
عندما نجد الملف الذي نبحث عنه، نستخدم أدوات سطر الأوامر للتحقق من هيكلة. الأمر head يظهر لنا بعض الأسطر في الملف، يمكننا من إلقاء نظرة سريعة على محتوى الملف:
لتحميل البيانات، اضغط هنا.
!head others/babies.data
bwt gestation parity age height weight smoke
120 284 0 27 62 100 0
113 282 0 33 64 135 0
128 279 0 28 64 115 1
123 999 0 36 69 190 0
108 282 0 23 67 125 1
136 286 0 25 62 93 0
138 244 0 33 62 178 0
132 245 0 23 65 140 0
120 289 0 25 62 125 0
العدد الافتراضي للأسطر الذي يعرضها الأمر head هي أول 10 أسطر في الملف، يمكننا عرض آخر 10 أسطر باستخدام tail:
!tail others/babies.data
103 278 0 30 60 87 1
118 276 0 34 64 116 0
127 290 0 27 65 121 0
132 270 0 27 65 126 0
113 275 1 27 60 100 0
128 265 0 24 67 120 0
130 291 0 30 65 150 1
125 281 1 21 65 110 0
117 297 0 38 65 129 0
يمكننا طباعة كل محتوى الملف باستخدام الأمر cat. انتبه عند استخدام هذا الأمر، لأن طباعة الملفات ذات المحتوى الكثير قد يؤثر على الشيل:
!cat others/text.txt
"city","zip","street"
"Alameda","94501","1220 Broadway"
"Alameda","94501","429 Fair Haven Road"
"Alameda","94501","2804 Fernside Boulevard"
"Alameda","94501","1316 Grove Street"
في أحيان عديدة، استخدام head و tail يكفي لمعرفة هيكلة الملف. مثلاً يمكننا رؤية أن ملف babynames.csv يستخدم صيغة CSV:
لتحميل البيانات، اضغط هنا.
!head babynames.csv
Name,Sex,Count,Year
Mary,F,9217,1884
Anna,F,3860,1884
Emma,F,2587,1884
Elizabeth,F,2549,1884
Minnie,F,2243,1884
Margaret,F,2142,1884
Ida,F,1882,1884
Clara,F,1852,1884
Bertha,F,1789,1884
يمكننا قراءة ملفات CSV باستخدام بانداز والدالة pd.read_csv:
# تستخدم pd بشكل كبير كأختصار ل Pandas. سنستخدم دائماً pd كأسم مختصر للمكتبة بانداز.
import pandas as pd
pd.read_csv('babynames.csv')
| Year | Count | Sex | Name | |
|---|---|---|---|---|
| 1884 | 9217 | F | Mary | 0 |
| 1884 | 3860 | F | Anna | 1 |
| 1884 | 2587 | F | Emma | 2 |
| … | … | … | … | … |
| 1883 | 5 | M | Verna | 1891891 |
| 1883 | 5 | M | Winnie | 1891892 |
| 1883 | 5 | M | Winthrop | 1891893 |
1891894 rows × 4 columns
حجم الملفات
لاحظ أن قراءة الملف babynames.csv نتج عنها DataFrame تحتوي على أكثر من 2 مليون سطر. جميع أجهزة الكمبيوتر لديها قدرات محدودة لا تستطيع تجاوزها. وقد يحدث أن تصل لهذه المراحل مرات عديدة ويبدأ جهازك بالعمل ببطيء بسبب أن كثير من البرامج تعمل في نفس الوقت. نحاول دائماً على عدم الوصول لهذه المرحلة أثناء عملنا مع البيانات.
DataFrame: جدول ثنائي الأبعاد، يستخدم كثيراً مع البيانات المجدولة ويحتوي على أعمدة وصفوف. لمعلومات أكثر هنا.
في كثير من الحالات، نستخدم بيانات للتحليل يتم تجميعها من الإنترنت. وتشغل هذه الملفات جزء من مساحة التخزين في الجهاز. يحتاج بايثون للتعامل وتعديل هذه البيانات لقراءة البيانات عن طريق ذاكرة التخزين العشوائية RAM. حجم الذاكرة العشوائية يكون غالباً أصغر بكثير من حجم مساحة التخزين.
كلاهما، مساحة التخزين وذاكرة التخزين العشوائية، يستخدمون البايت Byte لقياس مساحتها. تقريباً، كل حرف في ملف نصي عبارة عن بايت واحد. مثلاً ملف يحتوي على 177 حرفاً يشغل مساحة 177 بايت من مساحة التخزين.
بالطبع الكثير من البيانات التي نعمل عليها اليوم تحتوي على الكثير من الحروف، لوصف حجم الملفات ذات الحجم الكبير، نستخدم التالي:
| عدد البايت | الرمز | المضاعف |
|---|---|---|
| $1024 = 2^{10}$ | KiB | Kibibyte |
| $1024^2 = 2^{20}$ | MiB | Mebibyte |
| $1024^3 = 2^{30}$ | GiB | Gibibyte |
| $1024^4 = 2^{40}$ | TiB | Tebibyte |
| $1024^5 = 2^{50}$ | PiB | Pebibyte |
مثلاً، ملف يحتوي على 52428800 حرفاً، يشغل مساحة 52428800 بايت = 50 ميبيبايت = 50 MiB.
\[\frac {52428800 \text { byte}}{1024} = 51200 \text { KiB}\]
\[\frac {52428800 \text { byte}}{1024^2} = \frac {52428800}{1048576} = 50 \text { MiB}\]
لماذا نستخدم مضاعفات 1024 بدلاً من 1000؟ لأن جميع أجهزة الكمبيوتر تستخدم نظام العد الثنائي Binary Numbers وفيها مضاعفات 2 أسهل للاستخدام. سترى أيضاً الوحدات المعروفة دولياً تستخدم لحساب أحجام الملفات، مثل كيلو بايت، ميقا بايت وقيقا بايت. للأسف تستخدم هذه الوحدات بشكل غير متفق عليه. أحياناً يقصد بالكيلو بايت 1000 بايت، ومرات أخرى يقصد 1024 بايت. للتخلص من هذا الالتباس، سنستخدم الكيبي، ميبي، والجيبي بايت والتي تصف بشكل دقيق مضاعفات 1024.
متى يكون آمناً قراءة الملف؟
قبل البدء في تحليل البيانات، نحتاج أن نتأكد أن أحجام الملفات التي سنعمل عليها يمكن التحكم بها. ونستخدم لذلك أداة سطر الأوامر والأمرين ls و du:
!ls others
babies.data text.txt
أوامر سطر الأوامر يمكن إضافة بعض المتغيرات عليها لتقدم لنا مزيداً من المعلومات. مثلاً، إضافة -l للأمر يعطينا التالي:
!ls -l others
total 80
-rw-r--r--@ 1 sam staff 34654 Dec 19 13:34 babies.data
-rw-r--r-- 1 sam staff 177 Dec 19 13:37 text.txt
العمود الخامس من النتيجة السابقة للأمر تعطينا حجم الملف بالبايت. ونرى أن الملف babies.data يشغل 34654 بايت. لجعل القيمة أكثر سهولة للقراءة نستخدم الأمر -h:
!ls -l -h others
total 80
-rw-r--r--@ 1 sam staff 34K Dec 19 13:34 babies.data
-rw-r--r-- 1 sam staff 177B Dec 19 13:37 text.txt
نرى الآن أن الملف يشغل 34 كيبي بايت. رغم أن الملف babynames.csv يحتوي على أكثر من 2 مليون سطر، إلا أنة يشغل فقط 30 ميبي بايت.
!ls -l -h
total 62896
-rw-r--r-- 1 sam staff 30M Aug 10 22:35 babynames.csv
drwxr-xr-x 4 sam staff 128B Dec 19 13:37 others
-rw-r--r-- 1 sam staff 118K Sep 25 17:13 pandas_apply_strings_plotting.ipynb
-rw-r--r-- 1 sam staff 34K Sep 25 17:13 pandas_grouping_pivoting.ipynb
-rw-r--r-- 1 sam staff 32K Dec 19 13:07 pandas_indexes.ipynb
-rw-r--r-- 1 sam staff 2.1K Dec 19 13:23 pandas_intro.ipynb
-rw-r--r-- 1 sam staff 23K Dec 19 13:44 pandas_structure.ipynb
حجم المجلدات
في بعض الأحيان نريد معرفة حجم مجلد بدلاً من حجم الملفات. نلاحظ أن ls لا تعطي حجم المجلدات بشكل صحيح. مثلاً هنا حجم المجلد others هو 128 بايت.
!ls -l -h
total 62896
-rw-r--r-- 1 sam staff 30M Aug 10 22:35 babynames.csv
drwxr-xr-x 4 sam staff 128B Dec 19 13:37 others
-rw-r--r-- 1 sam staff 118K Sep 25 17:13 pandas_apply_strings_plotting.ipynb
-rw-r--r-- 1 sam staff 34K Sep 25 17:13 pandas_grouping_pivoting.ipynb
-rw-r--r-- 1 sam staff 32K Dec 19 13:07 pandas_indexes.ipynb
-rw-r--r-- 1 sam staff 2.1K Dec 19 13:23 pandas_intro.ipynb
-rw-r--r-- 1 sam staff 23K Dec 19 13:44 pandas_structure.ipynb
ولكن المجلد يحتوي على ملفات أكبر من 128 بايت:
!ls -l -h others
total 80
-rw-r--r--@ 1 sam staff 34K Dec 19 13:34 babies.data
-rw-r--r-- 1 sam staff 177B Dec 19 13:37 text.txt
لحساب حجم الملفات داخل المجلدات بشكل صحيح، نستخدم الأمر du. بشكل تلقائي، الأداة du تظهر حجم الملفات بصيغة المجموعات أو الكُتل blocks: 📝
!du others
80 others
لعرض الحجم بالبايت نستخدم -h:
!du -h others
40K others
في العادة نضيف الأمر -s لـ du لعرض جميع أحجام الملفات والمجلدات معاً. النجمة * في others/* تعني أن على du إظهار معلومات جميع الملفات داخل المجلد other:
!du -sh others/*
36K others/babies.data
4.0K others/text.txt
الذاكرة غير المباشرة
قاعدة عامة، قراءة ملف باستخدام مكتبة بانداز عادة ما يحتاج أن تكون ذاكرة الجهاز ضعف حجم الملف نفسه. مثلاً قراءة ملف بحجم 1 جيبي بايت يحتاج أن يكون الجهاز يحتوي على ذاكرة بحجم 2 جيبي بايت.
جميع البرامج تستخدم الذاكرة للعمل، بما في ذلك نظام التشغيل، متصفح الإنترنت، وكذلك جوبتر نوت بوك. جهاز ب 4 جيبي بايت قد لا يحتوي سوى على 1 جيبي بايت متوفرة للاستخدام إذا كان الكثير من البرامج يعملون في نفس الوقت. بحجم 1 جيبي بايت من الذاكرة المتوفرة للاستخدام من الصعب على بانداز قراءة ملف بحجم 1 جيبي بايت.
ملخص
في هذا الجزء، تعرفنا على هيكلة البيانات وجدولتها والتي سنستخدمها كثيراً في بقية الكتاب. كذلك عرضنا بعض الأوامر في أداة سطر الأوامر مثل ls ، du، head و tail. هذه الأوامر تساعدنا على فهم شكل الملفات التي سنعمل عليها. استخدمنا نفس الأدوات للتحقق من قدرة بانداز على قراءة الملفات. عندما تقرأ بانداز الملف، سيكون لدينا DataFrame جاهز للتحليل.
الفهرسة، التقسيم والترتيب
مقدمة
في ما تبقى من هذا الفصل سنعمل على نفس بيانات أسماء الأطفال التي سبق أن تحدثنا عنها في الفصل الأول. سنطرح سؤالاً، ثم نقسم السؤال إلى عدة أقسام، ونترجم كل جزء إلى كود برمجي في بايثون باستخدام مكتبة بانداز.
أولاً نقوم باستدعاء مكتبة بانداز:
import pandas as pd
بعد أن استدعيناها، يمكننا الآن قراء البيانات باستخدام الدالة pd.read_csv (معلومات أكثر عن الدالة هنا):
baby = pd.read_csv('babynames.csv')
baby
| Year | Count | Sex | Name | |
|---|---|---|---|---|
| 1884 | 9217 | F | Mary | 0 |
| 1884 | 3860 | F | Anna | 1 |
| 1884 | 2587 | F | Emma | 2 |
| … | … | … | … | … |
| 1883 | 5 | M | Verna | 1891891 |
| 1883 | 5 | M | Winnie | 1891892 |
| 1883 | 5 | M | Winthrop | 1891893 |
1891894 rows × 4 columns
لاحظ، لكي يعمل الكود البرمجي في الأعلى يجب أن يكون ملف babynames.csv متواجد في نفس المجلد الذي نعمل عليه، يمكننا التحقق من الملفات الموجودة في المجلد باستخدام الأمر ls:
!ls
babynames.csv pandas_indexes.ipynb
others pandas_intro.ipynb
pandas_apply_strings_plotting.ipynb pandas_structure.ipynb
pandas_grouping_pivoting.ipynb
عندما نستخدم مكتبة بانداز لقراءة البيانات، يتم تحويلها بشكل أوتوماتيكي إلى DataFrame. لكل عمود اسم، مثلاً ( ‘Name’، ‘Sex’، ‘Count’، ‘Year’) ولكل سطر رقم مفهرس، مثلاً (0، 1، 2، …، 1891893).
مسميات الأعمدة في ال DataFrame يطلق عليها Labels ولكل عمود رقم فهرسي Index، اسم العمود والرقم الفهرسي تسهل علينا الكثير في التعامل مع البيانات. الصفوف أيضاً لها أرقام فهرسيه Indexes.
لنستخدم بانداز للإجابة على السؤال التالي:
ما هي أسماء الأطفال الأكثر شهره في عام 2016؟
نبدأ أولاً بتقسيم المشكلة
لتسهيل الإجابة، يمكننا تقسيم السؤال إلى جزأين:
- تقسيم البيانات وسحب بيانات عام 2016 فقط.
- الترتيب تنازلياً حسب التكرار بإستخادم عمود Count.
التقسيم باستخدام .loc
لاختيار جزء من DataFrame، نستخدم .loc المتغير الأول فيها هو اسم السطر والثاني هو اسم العمود:
# السطر رقم 1
# العمود Name
baby.loc[1, 'Name']
'Anna'
لسحب أكثر من سطر أو عمود، نستخدم :
# نطلب هنا السطر 1 إلى 5
# والأعمدة من Name حتى Count
baby.loc[1:5, 'Name':'Count']
| Count | Sex | Name | |
|---|---|---|---|
| 3860 | F | Anna | 1 |
| 2587 | F | Emma | 2 |
| 2549 | F | Elizabeth | 3 |
| 2243 | M | Minnie | 4 |
| 2142 | M | Margaret | 5 |
أحياناً، نريد عمود واحد فقط من ال DataFrame، نستخدم التالي:
baby.loc[:, 'Year']
0 1884
1 1884
2 1884
...
1891891 1883
1891892 1883
1891893 1883
Name: Year, Length: 1891894, dtype: int64
عندما نختار عمود واحد فقط، تتحول ال DataFrame إلى مجموعة Series. المجموعة هي مصفوفة NumPy أحادية البعد يمكن أن نقوم بعمليات حسابية على جميع محتوياتها:
baby.loc[:, 'Year'] * 2
0 3768
1 3768
2 3768
...
1891891 3766
1891892 3766
1891893 3766
Name: Year, Length: 1891894, dtype: int64
لإختيار أعمدة معينة فقط، يمكننا تمرير مصفوفة بداخل .loc:
baby.loc[:, ['Name', 'Year']]
| Year | Name | |
|---|---|---|
| 1884 | Mary | 0 |
| 1884 | Anna | 1 |
| 1884 | Emma | 2 |
| … | … | … |
| 1883 | Verna | 1891891 |
| 1883 | Winnie | 1891892 |
| 1883 | Winthrop | 1891893 |
1891894 rows × 2 columns
طريقة أخرى لإيجاد بيانات عمود واحد:
# اختصاراً ل baby.loc[:, 'Name']
baby['Name']
0 Mary
1 Anna
2 Emma
...
1891891 Verna
1891892 Winnie
1891893 Winthrop
Name: Name, Length: 1891894, dtype: object
# اختصاراً ل baby.loc[:, ['Name', 'Count']]
baby[['Name', 'Count']]
| Count | Name | |
|---|---|---|
| 9217 | Mary | 0 |
| 3860 | Anna | 1 |
| 2587 | Emma | 2 |
| … | … | … |
| 5 | Verna | 1891891 |
| 5 | Winnie | 1891892 |
| 5 | Winthrop | 1891893 |
1891894 rows × 2 columns
التقسيم المشروط
لإيجاد الصفوف لسنة 2016 فقط، يجب أن نجد أولاً مجموعة Series تحتوي على True و False ( صح أو خطأ )، فيها True لكل قيمة نريدها و False للقيم التي لا نريدها. مجموعة السنوات:
# لإيجاد السنوات
baby['Year']
0 1884
1 1884
2 1884
...
1891891 1883
1891892 1883
1891893 1883
Name: Year, Length: 1891894, dtype: int64
# مقارنة كل سطر مع السنة 2016
baby['Year'] == 2016
0 False
1 False
2 False
...
1891891 False
1891892 False
1891893 False
Name: Year, Length: 1891894, dtype: bool
بهذه الطريقة تتم المقارنه بين كل سطر والسنه 2016، في حال كان السطر يساوي 2016 يظهر True والعكس إذا كانت لا تساوي False، يمكننا دمجها مع .loc:
# نريد التقسيم بالإسطر، لذا نضع شرطنا في المتغير الأول في .loc
baby_2016 = baby.loc[baby['Year'] == 2016, :]
baby_2016
| Year | Count | Sex | Name | |
|---|---|---|---|---|
| 2016 | 19414 | F | Emma | 1850880 |
| 2016 | 19246 | F | Olivia | 1850881 |
| 2016 | 16237 | F | Ava | 1850882 |
| … | … | … | … | … |
| 2016 | 5 | M | Zyahir | 1883745 |
| 2016 | 5 | M | Zyel | 1883746 |
| 2016 | 5 | M | Zylyn | 1883747 |
32868 rows × 4 columns
ترتيب الصفوف
بعد أن وجدنا فقط أسماء أطفال 2016، الخطوة التالية هي ترتيب الأسماء تنازلياً بناءاً على عمود Count. سنستخدم الدالة sort_values():
sorted_2016 = baby_2016.sort_values('Count', ascending=False)
sorted_2016
| Year | Count | Sex | Name | |
|---|---|---|---|---|
| 2016 | 19414 | F | Emma | 1850880 |
| 2016 | 19246 | F | Olivia | 1850881 |
| 2016 | 19015 | M | Noah | 1869637 |
| … | … | … | … | … |
| 2016 | 5 | F | Mikaelyn | 1868752 |
| 2016 | 5 | F | Miette | 1868751 |
| 2016 | 5 | M | Zylyn | 1883747 |
32868 rows × 4 columns
القيمة التلقائية للمتغير Ascending والذي يعني الترتيب تصاعدياً هي True، وإذا رغبنا ترتيب القيم تنازلياً، نضيف False للمتغير. معلومات أكثر هنا.
الآن، سنستخدم .iloc لإيجاد أول خمس أسطر من ال DataFrame. تعمل .iloc تماماً مثل .loc ولكن تأخذ قيم رقمية بدلاً من نصية / أسماء أعمدة. ولا تحسب آخر رقم كما في بايثون.
# إيجاد السطر رقم 0 والعمود رقم 0
sorted_2016.iloc[0, 0]
'Emma'
# إيجاد أول خمس أسطر
sorted_2016.iloc[0:5]
| Year | Count | Sex | Name | |
|---|---|---|---|---|
| 2016 | 19414 | F | Emma | 1850880 |
| 2016 | 19246 | F | Olivia | 1850881 |
| 2016 | 19015 | M | Noah | 1869637 |
| 2016 | 18138 | M | Liam | 1869638 |
| 2016 | 16237 | F | Ava | 1850882 |
الملخص
لدينا الآن أكثر خمس أسماء شهره في عام 2016، وتعلمنا كيف نستخدم الخمس دوال التالية في مكتبة بانداز:
| الدالة | العملية |
|---|---|
pd.read_csv() |
قراءة ملف CSV |
.loc أو .iloc |
التقسيم باستخدام أسماء الأعمدة أو ترتيبها الرقمي |
استخدام True/False داخل الدالة .loc |
التقسيم الشرطي |
.sort_values() |
الترتيب |
التجميع والجداول المحورية
في هذا الجزء، سنجيب على السؤال التالي:
ما هي الأسماء الأكثر شهره بين الذكور والإناث كل سنه؟
تقسيم المشكلة
نلاحظ أن السؤال مشابه للسؤال في الجزء السابق؛ السؤال السابق يريد فقط أسماء سنوات 2016 بينما هذا السؤال يشمل جميع السنوات. نقسم السؤال إلى قسمين:
- نجمع الأسطر حسب عامودي السنة Year و الجنس Sex.
- لكل مجموعة، أبحث عن الاسم الأكثر شهره.
معرفة الدوال التي تستخدم في حل مشكلة قد يبدو صعباً. عادةً، عن العمل بخطوات طويلة معقدة تشعر بأنة قد يكون هناك طريقة أسهل لفعل الخطوات هذه، إذا لم نعلم أنه يجب أن نقوم بالجمع مباشره، فيمكن أن نكتب خطوات كالتالي:
- الدوران Loop بين كل سنة على حدة.
- لكل سنة، الدوران في عمود الجنس.
- لكل سنة وجنس، أوجد الاسم الأكثر شهره.
في بانداز، هناك دائماً طريقة أفضل من الدوران. الدوران على القيم في ال DataFrame يجب أن يستبدل بالتجميع.
التجميع
للتجميع في بانداز، نستخدم الدالة .groupby():
baby.groupby('Year')
<pandas.core.groupby.DataFrameGroupBy object at 0x1a14e21f60>
عند استخدام الدالة .groupby() تعود لنا بكائن Object من نوع DataFrameGroupBy. يمكننا استخدام .agg() مع دالة تجميع على هذا الكائن للحصول على نتيجة يمكن قرائتها:
الدالة
.agg()تسمح لنا باستخدام دوال على جميع الأعمدة. 📝
# دالة تجميع هي أي دالة تقبل متغير، هنا مثلاً أستخدمنا مجموعة/مصفوفة، وينتج عنها نتيجة واحدة (رقم مثلاً)، هنا تعود طول المجموعة
def length(series):
return len(series)
# حساب عدد الأصفف في كل سنة
baby.groupby('Year').agg(length)
| Count | Sex | Name | |
|---|---|---|---|
| Year | |||
| 2000 | 2000 | 2000 | 1880 |
| 1935 | 1935 | 1935 | 1881 |
| 2127 | 2127 | 2127 | 1882 |
| … | … | … | … |
| 33206 | 33206 | 33206 | 2014 |
| 33063 | 33063 | 33063 | 2015 |
| 32868 | 32868 | 32868 | 2016 |
137 rows × 3 columns
تلاحظ أيضاً، ان الدالة التي عرفناها بأسم length تستدعي دالة أخرى بأسم len، لتبسيط الكود البرمجي يمكننا عمل التالي:
baby.groupby('Year').agg(len)
| Count | Sex | Name | |
|---|---|---|---|
| Year | |||
| 2000 | 2000 | 2000 | 1880 |
| 1935 | 1935 | 1935 | 1881 |
| 2127 | 2127 | 2127 | 1882 |
| … | … | … | … |
| 33206 | 33206 | 33206 | 2014 |
| 33063 | 33063 | 33063 | 2015 |
| 32868 | 32868 | 32868 | 2016 |
137 rows × 3 columns
تم تطبيق التجميع على كل الأعمدة في ال DataFrame، نتج عن ذلك تكرار في حساب النتائج. يمكننا تحديد نتائج معينة عبر تقسيم الأعمدة قبل التجميع.
year_rows = baby[['Year', 'Count']].groupby('Year').agg(len)
year_rows
# طريقة أخرى لتقصير هذا الكود البرمجي عن طريق عمل التالي:
#
# year_counts = baby[['Year', 'Count']].groupby('Year').count()
#
# بانداز قامت بإختصار الكثير من دوال التجميع مثل count, sum و mean.
| Count | |
|---|---|
| Year | |
| 2000 | 1880 |
| 1935 | 1881 |
| 2127 | 1882 |
| … | … |
| 33206 | 2014 |
| 33063 | 2015 |
| 32868 | 2016 |
137 rows × 1 columns
لاحظ أن أرقام الأسطر Indexes تم تغيرها للسنوات، يمكننا الآن التقسيم حسب السنة بواسطة .loc كما تعلمنا سابقاً:
# إيجاد كل عشرين سنه بدءًا من 1880
year_rows.loc[1880:2016:20, :]
| Count | |
|---|---|
| Year | |
| 2000 | 1880 |
| 3730 | 1900 |
| 10755 | 1920 |
| 8961 | 1940 |
| 11924 | 1960 |
| 19440 | 1980 |
| 29764 | 2000 |
التجميع بأكثر من عمود
كما تعلمنا في المادة السابقة داتا 8، يمكننا التجميع بأكثر من عمود لإيجاد نتائج بناءاً عليهم. لفعل ذلك، نقوم بتمرير قائمة بأسماء الأعمدة كمتغيرات للدالة .groupby():
grouped_counts = baby.groupby(['Year', 'Sex']).sum()
grouped_counts
| Count | ||
|---|---|---|
| Sex | Year | |
| 90992 | F | 1880 |
| 110491 | M | |
| 91953 | F | 1881 |
| … | … | … |
| 1907211 | M | 2015 |
| 1756647 | F | 2016 |
| 1880674 | M |
274 rows × 1 columns
الكود البرمجي السابق يحسب مجموع الأطفال المولودين كل سنة لكل جنس. لنقوم الآن بجمع أكثر من عمود لحساب الأسماء الأكثر شهره لكل جنس وسنة. بما أن البيانات مرتبة تنازلياً بناءًا على العمود Count، يمكننا تعريف دالة تجميع تجلب لنا أول قيمة في كل مجموعة. (إذا كانت البيانات غير مرتبه، نستخدم الدالة sort_values() أولاً ):
# الأسم الأكثر شهره هو أول قيمة في المجموعة (بما أنها مرتبة من الأعلى للأدنى)
def most_popular(series):
return series.iloc[0]
baby_pop = baby.groupby(['Year', 'Sex']).agg(most_popular)
baby_pop
| Count | Name | ||
|---|---|---|---|
| Sex | Year | ||
| 7065 | Mary | F | 1880 |
| 9655 | John | M | |
| 6919 | Mary | F | 1881 |
| … | … | … | … |
| 19594 | Noah | M | 2015 |
| 19414 | Emma | F | 2016 |
| 19015 | Noah | M |
274 rows × 2 columns
لتوضيح الكود البرمجي السابق، يمكن مشاهدة نتيجة الأمر
baby.groupby(['Year', 'Sex'])بإضافة.apply(print)ليصبح الكود بشكل كاملbaby.groupby(['Year', 'Sex']).apply(print)النتيجة هنا مجموعة Series بأحجام مختلفه لكل سنة على حدة. تحتوي فيها على 4 أعمدةName،Sex،Count،Yearمثال لسنة 1880:
Year Count Sex Name 1880 7065 F Mary 0 1880 2604 F Anna 1 1880 2003 F Emma 2 … … … … … 1880 5 M Verona 1884687 1880 5 M Vertie 1884688 1880 5 M Wilma 1884689 عند استخدام الدالة التجميعية التي قمنا بتعريفها
most_popularتقوم الدالة بإيجاد أول قيمة / سطر في المجموعة والذي يحتوي على عامودينNameوCount، يتم تجميعها مع العامودينYearوSexلتتكون لنا نتيجة المطلوبة.
لاحظ أن التجميع بأكثر من عمود ينتج أكثر من مسمى للسطر. يسمى ذلك بالأسطر متعددة المستويات. يجب أن تعرف أن .loc تقبل مصفوفة من نوع صفوف Tuples بأسماء الأسطر بدلاً من قيمة واحدة:
baby_pop.loc[(2000, 'F'), 'Name']
'Emily'
ولكن لاستخدام .iloc، يمكننا إرسال الأرقام دون مصفوفة صفوف Tuples، كما فعلنا بالمثال السابق، لأن الدالة تقبل الأرقام فقط:
# السطر من 10 حتى 15، وجميع الأعمدة
baby_pop.iloc[10:15, :]
| Count | Name | ||
|---|---|---|---|
| Sex | Year | ||
| 9128 | Mary | F | 1885 |
| 8756 | John | M | |
| 9889 | Mary | F | 1886 |
| 9026 | John | M | |
| 9888 | Mary | F | 1887 |
الجداول المحورية
إذا جمعنا البيانات بناءاً على عامودين، فمن الأفضل استخدام الجداول المحورية Pivot Tables لتمثيل البيانات كونها تظهر لنا النتائج بشكل أكثر وضوحاً. لبناء الجداول المحورية نستخدم الدالة pd.pivot_table(): 📝
pd.pivot_table(baby,
index='Year', # عمود الأسم/الفهرس للأسطر
columns='Sex', # الأعمدة
values='Name', # القيم داخل الأعمدة
aggfunc=most_popular) # دالة التجميع
| M | F | Sex |
|---|---|---|
| Year | ||
| John | Mary | 1880 |
| John | Mary | 1881 |
| John | Mary | 1882 |
| … | … | … |
| Noah | Emma | 2014 |
| Noah | Emma | 2015 |
| Noah | Emma | 2016 |
137 rows × 2 columns
لنقارنها بنتيجة baby_pop عندما استخدامنا الدالة .groupby()، يمكننا ملاحظة أن الأعمدة أصبحت مقسمة حسب الجنس بدلاً من أن كانت مفهرسة Index:
baby_pop
| Count | Name | ||
|---|---|---|---|
| Sex | Year | ||
| 7065 | Mary | F | 1880 |
| 9655 | John | M | |
| 6919 | Mary | F | 1881 |
| … | … | … | … |
| 19594 | Noah | M | 2015 |
| 19414 | Emma | F | 2016 |
| 19015 | Noah | M |
274 rows × 2 columns
الملخص
لدينا الآن أكثر الأسماء شهره لكل جنس في كُل سنة، وتعلمنا كيف نستخدم الدوال التالية في مكتبة بانداز:
| الدالة | العملية |
|---|---|
f.groupby(label) |
التجميع |
df.groupby([label1, label2]) |
تجميع أكثر من عمود |
df.groupby(label).agg(func) |
التجميع واستخدام الدوال على الأعمدة |
pd.pivot_table() |
الجداول المحورية |
دالة التطبيق، النصوص والرسم البياني
سنجيب في هذا الجزء على السؤال التالي:
هل يمكننا استخدام آخر حرف من الاسم لتوقع جنس الطفل؟
سنستخدم نفس البيانات babynames.csv:
baby = pd.read_csv('babynames.csv')
baby.head()
# الدالة .head() تظهر لنا أول خمس أسطر في البيانات
| Year | Count | Sex | Name | |
|---|---|---|---|---|
| 1884 | 9217 | F | Mary | 0 |
| 1884 | 3860 | F | Anna | 1 |
| 1884 | 2587 | F | Emma | 2 |
| 1884 | 2549 | F | Elizabeth | 3 |
| 1884 | 2243 | F | Minnie | 4 |
تحديد أجزاء المشكلة
توجد طُرق كثيره للتنبؤ، لكن سنستخدم هنا الرسم البياني. سنقسم المشكلة إلى الخطوات التالية:
- إيجاد آخر حرف من كل اسم.
- تجميع آخر حرف مع الجنس، التجميع وإيجاد مجموع الأطفال.
- رسم النتائج لكل جنس وآخر حرف.
دالة التطبيق
تحتوي المجموعات Series في بانداز على دالة .apply()، التي تستقبل دوال وتطبق هذه الدالة على جميع القيم:
names = baby['Name']
names.apply(len)
0 4
1 4
2 4
..
1891891 5
1891892 6
1891893 8
Name: Name, Length: 1891894, dtype: int64
في المثال السابق، استخدم الكاتب
.apply()لإيجاد طول كل اسم في المجموعة عن طريق أولاً وضع الأسماء في متغيرnamesثم تطبيق دالةlenعلى جميع القيم.
لاستخراج آخر حرف من كل اسم، سنقوم بكتابة دالة وتمريرها في دالة التطبيق .apply():
def last_letter(string):
return string[-1]
names.apply(last_letter)
0 y
1 a
2 a
..
1891891 a
1891892 e
1891893 p
Name: Name, Length: 1891894, dtype: object
أستخدم الكاتب في دالة
last_letterالقيمةstring[-1]والتي تعني آخر حرف في النص. لمزيد من المعلومات عن التعامل مع النصوص هنا و هنا.
التلاعب بالنصوص
رغم مرونة الدالة .apply()، إلا أنه من الأسرع استخدام الدوال الموجودة في بانداز للتعامل مع النصوص. يوجد الكثير من الدوال الموجودة للتعامل مع النصوص باستخدام .str في المجموعات:
names = baby['Name']
names.str.len()
0 4
1 4
2 4
..
1891891 5
1891892 6
1891893 8
Name: Name, Length: 1891894, dtype: int64
ويمكننا استخراج آخر حرف من كل اسم بالطريقة التالية:
names.str[-1]
0 y
1 a
2 a
..
1891891 a
1891892 e
1891893 p
Name: Name, Length: 1891894, dtype: object
نقترح قراءة المزيد عن دوال النصوص في باندز عن طريق الرابط هنا.
يمكننا الآن إضافة عمود آخر حرف لبيانات الأطفال لدينا:
baby['Last'] = names.str[-1]
baby
| Last | Year | Count | Sex | Name | |
|---|---|---|---|---|---|
| y | 1884 | 9217 | F | Mary | 0 |
| a | 1884 | 3860 | F | Anna | 1 |
| a | 1884 | 2587 | F | Emma | 2 |
| … | … | … | … | … | … |
| a | 1883 | 5 | M | Verna | 1891891 |
| e | 1883 | 5 | M | Winnie | 1891892 |
| p | 1883 | 5 | M | Winthrop | 1891893 |
1891894 rows × 5 columns
التجميع
لإيجاد توزيع الجنس بناءاً على آخر حرف، نحتاج لجمع العامودين Last و Sex:
# استخدمنا طريقة مختصرة بدلاً من: baby.groupby(['Last', 'Sex']).agg(np.sum)
baby.groupby(['Last', 'Sex']).sum()
| Year | Count | ||
|---|---|---|---|
| Sex | Last | ||
| 915565667 | 58079486 | F | a |
| 53566324 | 1931630 | M | |
| 1092953 | 17376 | F | b |
| … | … | … | … |
| 114394474 | 18569388 | M | y |
| 4268028 | 142023 | F | z |
| 19015 | 9649274 | M |
52 rows × 2 columns
لاحظ أنه تم جمع عمود السنة، لأنه يتم جمع أي عمود لا يتم تمريرة لدالة التجميع .groupby(). ولحل هذه المشكلة يمكننا تحديد الأعمدة التي نرغب باستخدامها قبل تمريرها لدالة التجميع:
# عندما تكون الأسطر طويلة، يمكننا جمعها في أقواس `()`
# ونجعل كل دالة في سطر منفصل.
letter_dist = (
baby[['Last', 'Sex', 'Count']]
.groupby(['Last', 'Sex'])
.sum()
)
letter_dist
| Count | ||
|---|---|---|
| Sex | Last | |
| 58079486 | F | a |
| 1931630 | M | |
| 17376 | F | b |
| … | … | … |
| 18569388 | M | y |
| 142023 | F | z |
| 9649274 | M |
52 rows × 1 columns
الرسم البياني
تحتوي بانداز على دوال للرسم البياني والتي تحتوي على الرسوم البيانية البسيطة مثل المخطط الشريطي Bar Chart، المدرج التكراري Histogram، المخطط البياني الخطي Line Chart و مخطط التشتت Scatter plot. للرسم نستخدم الدالة .plot:
# نستخدم المتغير figsize لتحديد حجم الرسم البياني
letter_dist.plot.barh(figsize=(10, 10))
<matplotlib.axes._subplots.AxesSubplot at 0x1a17af4780>
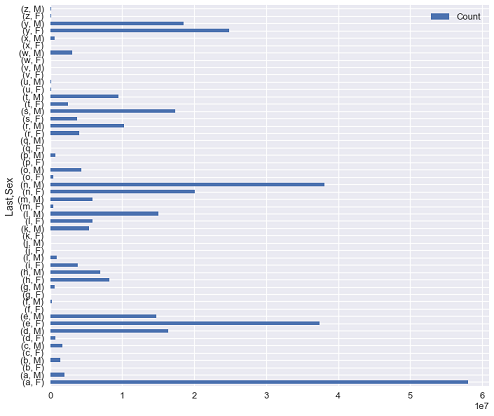
رغم أن الرسم البياني يوضح توزيع آخر حرف مع الجنس، يصعب التفريق بين شريط الذكور والإناث. بالرجوع لشرح الرسم البياني في مكتبة بانداز (هنا) نرى أن بانداز تقوم برسم شريط لكل سطر، وكلاهما بنفس اللون. لذا فاستخدام نسخة الجدول المحوري هنا لبياناتنا ستظهر الرسم البياني بشكل أوضح:
letter_pivot = pd.pivot_table(
baby, index='Last', columns='Sex', values='Count', aggfunc='sum'
)
letter_pivot
| M | F | Sex |
|---|---|---|
| Last | ||
| 1931630 | 58079486 | a |
| 1435939 | 17376 | b |
| 1672407 | 30262 | c |
| … | … | … |
| 644092 | 37381 | x |
| 18569388 | 24877638 | y |
| 120123 | 142023 | z |
26 rows × 2 columns
استخدم الكاتب هنا
pivot_tableمع متغيرات مختلفة ليحدد كل قيمة بناءًا على العمود المخصص لها، الرقم الفهرسيIndexحدد ليكون عمود آخر حرفLast، حدد الأعمدة هنا وهي الجنسين. حدد القيم داخل الأعمدة وهي عمودCountداخل المتغيرValues، وأخيراًaggfuncوحدد فيه دالة التجميع التي نرغب باستخدامهاSum. مزيد من التفصيل هنا و هنا.
letter_pivot.plot.barh(figsize=(10, 10))
<matplotlib.axes._subplots.AxesSubplot at 0x1a17c36978>
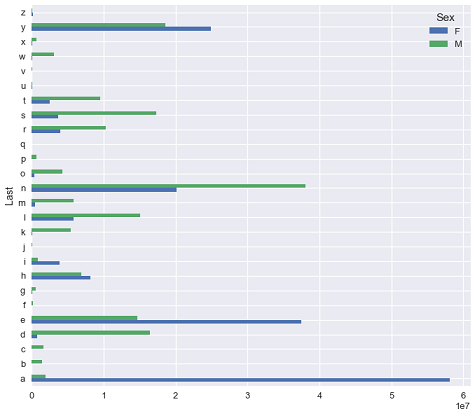
قامت بانداز بتكوين مفاتيح الرسم البياني Legends لنا. ولكن لا تزال لدينا مشكلة في الرسم، أظهرنا عدد النتائج لكل حرف وجنس وفي بعض الأحيان بدأت بعض الأشرطة طويلة جداً والبعض لا يبدو واضحاً أبداً. من الأفضل أن نظهر النسب المئوية للذكور والإناث في كل حرف بدلاً من المجاميع:
# قام الكاتب هنا بجمع عدد الذكور والإناث لكل حرف وجعلها في متغير جديد `total_for_each_letter`
total_for_each_letter = letter_pivot['F'] + letter_pivot['M']
# هنا قام بقسمة كل جنس من مجموع كُل حرف
letter_pivot['F prop'] = letter_pivot['F'] / total_for_each_letter
letter_pivot['M prop'] = letter_pivot['M'] / total_for_each_letter
letter_pivot
| M prop | F prop | M | F | Sex |
|---|---|---|---|---|
| Last | ||||
| 0.032188 | 0.967812 | 1931630 | 58079486 | a |
| 0.988044 | 0.011956 | 1435939 | 17376 | b |
| 0.982227 | 0.017773 | 1672407 | 30262 | c |
| … | … | … | … | … |
| 0.945147 | 0.054853 | 644092 | 37381 | x |
| 0.427403 | 0.572597 | 18569388 | 24877638 | y |
| 0.458229 | 0.541771 | 120123 | 142023 | z |
26 rows × 4 columns
(letter_pivot[['F prop', 'M prop']]
.sort_values('M prop') # ترتيب تنازلياً حسب نسبة الذكور
.plot.barh(figsize=(10, 10))
)
<matplotlib.axes._subplots.AxesSubplot at 0x1a18194b70>
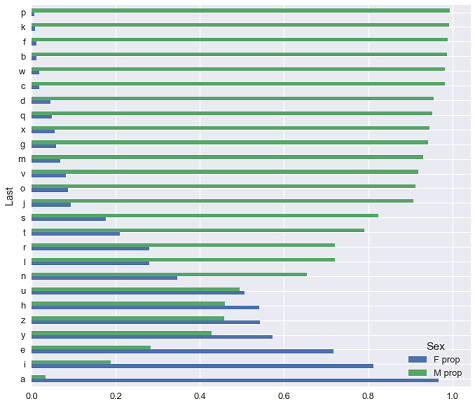
الملخص
نلاحظ أن غالبية الأسماء المنتهية بالحرف P هم ذكور والتي تنتهي بالحرف A هم إناث! بشكل عام، مسافات الأشرطة في الرسم البياني لكثير من الأحرف تمكنا من التوقع بشكل الصحيح بجنس الشخص بناءًا على آخر حرف من أسمة.
تعلمنا استخدام الدوال التالية في بانداز:
| الدالة | العملية |
|---|---|
series.apply(func) |
استخدام دالة على جميع القيم في المجموعة |
series.str.func()a |
التلاعب بالنصوص |
df.plot.func()a |
الرسم البياني |