مبادئ وتقنيات علم البيانات
الفصل التاسع: قواعد البيانات العلائقية و SQL
فهرس الفصل:
مقدمة
حتى الآن، قمنا بالتعامل مع بيانات محفوظه في ملفات نصيه على الكمبيوتر. على الرغم من سهولة التعامل مع البيانات ذات الحجم الصغير في التحليل، إلا أن استخدام الملفات النصية لحفظها يظهر لنا بعض التحديات في حالات كثيره عندما نعمل على بيانات حقيقية.
الكثير من البيانات يتم جمعها من قبل أشخاص مختلفين، فريق من علماء البيانات مثلاً. إذا تم حفظ البيانات في ملفات نصيه، سيحتاج الفريق لتحميل وإرسال البيانات في كل مرة يتم التعديل عليها. الملفات النصية وحدها لا توفر طريقة مناسبه لإستعادتها ومشاركتها ليتم استخدامها بين عدد مختلف من المحللين. هذه المشكلة، إضافة إلى مشاكل أخرى، تجعل التعامل مع الملفات النصية كبيرة الحجم صعباً خاصه بين فريق من المحللين.
عادةً ما ننتقل لأنظمة قواعد البيانات العلائقية (RDBMS) لحفظ البيانات، مثلاً MySQL أو PostgreSQL. للعمل على هذه الأنظمة، نستخدم لغة الاستعلام SQL بدلاً من بايثون. في هذا الفصل، سنتحدث عن قواعد البيانات العلائقية ونتعرف على SQL.
النموذج العلائقي
قاعدة البيانات هي مجموعة مُرتبه من البيانات. في السابق، كانت البيانات محفوظه ومصممه بشكل معين لتفي بغرض ما. مثلاً، شركة طيران قد تقوم بحفظ معلومات رحلة بطريقه مختلفة عن حفظ بنك لمعلومات حساب. في عام 1969، قام تيد كود Ted Codd بتعريف النموذج العلائقي كطريقه عامه لحفظ البيانات. البيانات محفوظه في جداول ثنائية الأبعاد تسمى علاقات Relations، تحتوي على ملاحظات معينة في كل صف (عادة ما تعرف بمصفوفات Tuples). كل مصفوفة تحتوي على بعض السمات Attributes والتي تصف العلاقات بين الجداول. كل سمه عن علاقة لديها اسم ونوع.
لنأخذ جدول العلاقات التالي purchases:
| name | product | retailer | date purchased |
|---|---|---|---|
| Samantha | iPod | Best Buy | 03-Jun-16 |
| Timothy | Chromebook | Amazon | 08-Jul-16 |
| Jason | Surface Pro | Target | 02-Oct-16 |
في purchases، كل صف يصف علاقة بين السمات name، product، retailer و date purchased.
مخطط العلاقات Relation schema تحتوي على أسماء الأعمدة، أنواع البيانات وقيودها. مثلاً، مخطط جدول purchases يحدد أن هناك الأعمدة name، product، retailer و date purchased، ويوضح أيضاً أن كل عمود يحتوي على نص.
جدول العلاقات التالي prices يوضح السعر الحالي لمنتجات في أسواق مختلفة:
| retailer | product | price |
|---|---|---|
| Best Buy | Galaxy S9 | 719.00 |
| Best Buy | iPod | 200.00 |
| Amazon | iPad | 450.00 |
| Amazon | Battery pack | 24.87 |
| Amazon | Chromebook | 249.99 |
| Target | iPod | 215.00 |
| Target | Surface Pro | 799.00 |
| Target | Google Pixel 2 | 659.00 |
| Walmart | Chromebook | 238.79 |
الآن يمكننا العودة لكلا الجدولين لتحديد كم دفع كل من Samantha، Timothy، و Jason لمنتجاتهم (لنفترض بقاء الأسعار كما هي في جميع الأسواق والأوقات). معاً، كلا الجدولين يكونا قاعدة بيانات علائقية، والتي هي عبارة عن جداول بينها أكثر من علاقة. المخطط لكامل قاعدة البيانات هي مصفوفة تحتوي على جميع مخططات العلاقات في قاعدة البيانات.
أنظمة قواعد البيانات العلائقية
يمكننا وصف قواعد البيانات العلائقية بأنها مجموعه من الجداول تحتوي على صفوف لمدخلات. نظام قاعدة بيانات علائقية (RDBMS) يوفر واجهه للمستخدم لتلك القواعد. Oracle، MySQL و PostgreSQL هي ثلاث من أكثر قواعد البيانات العلائقية إستخداماً.
توفر هذه الأنظمة المستخدم إمكانية إضافة، تعديل، وحذف البيانات منها. إضافة لعدد من المميزات لتميزها عن استخدام الملفات النصية لحفظ البيانات، وهي:
- ضمانية حفظ البيانات: تحمي هذه الأنظمة البيانات من مشاكل الأنظمة المختلفة.
- الأداء: تحفظ البيانات بشكل أكثر كفاءة من الملفات النصية ولديها خوارزميات صُممت بشكل متقن للاستعلام عن البيانات.
- إدارة البيانات: توفر أدوات للتحكم بالوصول للبيانات، للحماية من المستخدمين غير المصرح لهم بالوصول للبيانات الحساسة.
- تناسق البيانات: يمكن لهذه الأنظمة فرض قيود على المحتوى المُدخل، مثلاً، العمود
GPAيجب أن يحتوي فقط على رقم عشري من 0. 0 حتى 4. 0.
للتعامل مع البيانات المحفوظة فيه قواعد RDBMS نستخدم SQL.
RDBMS × بانداز
ما الفرق بين RDBMS وبانداز أولاً، بانداز لا تعتبر وسيلة لحفظ البيانات. على الرغم أن ال DataFrames في بانداز يمكنها الكتابة والقراءة من عدة أشكال للبيانات، لا يمكن لبانداز التحكم بطريقة حفظ البيانات في الكمبيوتر كما في RDBMS. ثانياً، بانداز توفر بشكل أساسي أدوات للتعامل مع البيانات، بينما RDBMS توفر طرق حفظ والتعامل مع البيانات معاً، مما يجعلها خياراً أفضل للبيانات ذات الحجم الكبير. من القواعد العامة هي أن نستخدم RDBMS عندنا تكون حجم البيانات لدينا أكثر من عدة قيقا بايت. أخيرا، للتعامل مع بانداز نحتاج لمعرفة ببايثون، بينما في RDBMS نحتاج لمعرفة SQL. وبما أن SQL أسهل بكثير للتعلم من بايثون، مما يجعل RDBMS سهله للتعامل من قبل المستخدمين غير التقنيين.
SQL
SQL (لغة الاستعلام الهيكلية) هي لغة برمجه لديها عمليات لتحديد، ترتيب، تعديل وإجراء العمليات الحسابية على بيانات محفوظه في أنظمة قواعد البيانات العلائقية (RDBMS).
تعتبر SQL لغة برمجه تعريفية. يعني ذلك أن المستخدم يجب أن يحدد أي نوع من البيانات يحتاج what، وليس كيف يحصل عليه how. للتوضيح:
- Declarative تعرفيه: قم بعملية حساب للأعمدة
xوyمن الجدولAعندما تكون القيمة في العمودyأكبر من 100.00. - Imperative أمرية: لكل قيمه في الجدول
A، تحقق أن كانت القيمة للمتغيرyأكثر من 100. إذا كانت كذلك، احفظ سمات الأعمدةxوyفي جدول جديد. وأظهر لنا الجدول الجديد.
في هذا الفصل، سنكتب استعلامات SQL كنصوص في بايثون، ثم نستخدم بانداز لتنفيذ هذه أوامر الاستعلام وقراءة النتائج ك DataFrame في بانداز أثناء شرحنا للأوامر في SQL، سنظهر طريقة كتابتها في بانداز للمقارنة بينهما.
تنفيذ أوامر الاستعلام في بانداز
لتنفيذ أوامر استعلام SQL في بايثون، سنقوم بالتواصل مع قاعدة البيانات باستخدام مكتبة sqlalchemy. يمكننا لاحقاً استخدام الدالة pd.read_sql لتنفيذ أوامر SQL.
لتحميل قاعدة البيانات sql_basics.db اضغط هنا.
import sqlalchemy
# pd.read_sql يقبل متغير engine يوصلنا بقاعدة البيانات، والذي انشأناه بالأسفل
sqlite_uri = "sqlite:///sql_basics.db"
sqlite_engine = sqlalchemy.create_engine(sqlite_uri)
تحتوي قاعدة البيانات على جدول علاقات واحد: prices. لإظهاره نستخدم أمر استعلام في SQL باستخدام الدالة read_sql على قاعدة البيانات العلائقية RDBMS، ثم تأتينا النتيجة ك DataFrame:
sql_expr = """
SELECT *
FROM prices
"""
pd.read_sql(sql_expr, sqlite_engine)
| price | product | retailer | |
|---|---|---|---|
| 719 | Galaxy S9 | Best Buy | 0 |
| 200 | iPod | Best Buy | 1 |
| 450 | iPad | Amazon | 2 |
| 24.87 | Battery pack | Amazon | 3 |
| 249.99 | Chromebook | Amazon | 4 |
| 215 | iPod | Target | 5 |
| 799 | Surface Pro | Target | 6 |
| 659 | Google Pixel 2 | Target | 7 |
| 238.79 | Chromebook | Walmart | 8 |
لاحقاً في هذا الفصل، سنقارن بين استعلامات SQL و دوال بانداز لذا قمنا بكتابة DataFrame تحتوي على نفس المحتوى السابق وحفظناها في المتغير prices:
import pandas as pd
prices = pd.DataFrame([['Best Buy', 'Galaxy S9', 719.00],
['Best Buy', 'iPod', 200.00],
['Amazon', 'iPad', 450.00],
['Amazon', 'Battery pack', 24.87],
['Amazon', 'Chromebook', 249.99],
['Target', 'iPod', 215.00],
['Target', 'Surface Pro', 799.00],
['Target', 'Google Pixel 2', 659.00],
['Walmart', 'Chromebook', 238.79]],
columns=['retailer', 'product', 'price'])
| price | product | retailer | |
|---|---|---|---|
| 719 | Galaxy S9 | Best Buy | 0 |
| 200 | iPod | Best Buy | 1 |
| 450 | iPad | Amazon | 2 |
| 24.87 | Battery pack | Amazon | 3 |
| 249.99 | Chromebook | Amazon | 4 |
| 215 | iPod | Target | 5 |
| 799 | Surface Pro | Target | 6 |
| 659 | Google Pixel 2 | Target | 7 |
| 238.79 | Chromebook | Walmart | 8 |
طريقة كتابة أوامر SQL
جميع أوامر الاستعلام في SQL تكون بهذا الشكل:
SELECT [DISTINCT] <column expression list>
FROM <relation>
[WHERE <predicate>]
[GROUP BY <column list>]
[HAVING <predicate>]
[ORDER BY <column list>]
[LIMIT <number>]
لاحظ أن:
- جميع ما في [داخل الأقواس] هي أوامر اختياريه. ليكون أمر الاستعلام صحيح يجب أن يحتوي على
SELECTوFROM. - في العادة تكتب أوامر الاستعلام في SQL بأحرف إنجليزية كبيرة. على الرغم أن تكبير الأحرف ليس مطلوب، لكن يعتبر من الطرق المتبعة الصحيحة لكتابة الأوامر، لتسهل على المستخدمين الآخرين قراءة استعلاماتك.
- في الأمر
FROMيمكننا الاستعلام عن أكثر من جدول، ولكن في هذا الفصل سنتدرب على استخدام جدول واحد لجعل الأمر سهلاً على المتعلم.
SELECT و FROM
الأمران الإلزاميان في استعلامات SQL هي:
SELECTوتعني الأعمدة التي نريد إظهارها.FROMويقصد بها الجداول التي نأخذ منها الأعمدة.
لعرض جميع محتوى جدول prices، نطبق الأمر:
sql_expr = """
SELECT *
FROM prices
"""
pd.read_sql(sql_expr, sqlite_engine)
| price | product | retailer | |
|---|---|---|---|
| 719 | Galaxy S9 | Best Buy | 0 |
| 200 | iPod | Best Buy | 1 |
| 450 | iPad | Amazon | 2 |
| 24.87 | Battery pack | Amazon | 3 |
| 249.99 | Chromebook | Amazon | 4 |
| 215 | iPod | Target | 5 |
| 799 | Surface Pro | Target | 6 |
| 659 | Google Pixel 2 | Target | 7 |
| 238.79 | Chromebook | Walmart | 8 |
الاستعلام SELECT * يجلب لنا جميع الأعمدة. لعرض فقط عمود retailer، نقوم بإضافتها كالتالي:
sql_expr = """
SELECT retailer
FROM prices
"""
pd.read_sql(sql_expr, sqlite_engine)
| retailer | |
|---|---|
| Best Buy | 0 |
| Best Buy | 1 |
| Amazon | 2 |
| Amazon | 3 |
| Amazon | 4 |
| Target | 5 |
| Target | 6 |
| Target | 7 |
| Walmart | 8 |
إذا أردنا عرض القيم في الجدول دون تكرار، نقوم بإضافة DISTINCT:
sql_expr = """
SELECT DISTINCT(retailer)
FROM prices
"""
pd.read_sql(sql_expr, sqlite_engine)
| retailer | |
|---|---|
| Best Buy | 0 |
| Amazon | 1 |
| Target | 2 |
| Walmart | 3 |
طريقة كتابة هذا الاستعلام في بانداز تكون كالتالي:
prices['retailer'].unique()
array(['Best Buy', 'Amazon', 'Target', 'Walmart'], dtype=object)
كل نظام قواعد بيانات يأتي بدوالة الخاصة التي يمكن تطبيقها، مثلاً دوال مقارنة، العمليات الحسابية، ودوال النصوص. في هذه المادة نستخدم PostgreSQL، نظام قواعد بيانات علائقي ويأتي معه بالكثير من الدوال. يمكن تصفح كامل الدوال هنا. تذكر دائماً أن كل نظام لديه دوالة الخاصة.
الاستعلام التالي يحول كل أسماء الأسواق إلى حروف كبيرة، ويقوم بقسمة سعر الشراء على 2:
sql_expr = """
SELECT
UPPER(retailer) AS retailer_caps,
product,
price / 2 AS half_price
FROM prices
"""
pd.read_sql(sql_expr, sqlite_engine)
| half_price | product | retailer_caps | |
|---|---|---|---|
| 359.5 | Galaxy S9 | BEST BUY | 0 |
| 100 | iPod | BEST BUY | 1 |
| 225 | iPad | AMAZON | 2 |
| 12.435 | Battery pack | AMAZON | 3 |
| 124.995 | Chromebook | AMAZON | 4 |
| 107.5 | iPod | TARGET | 5 |
| 399.5 | Surface Pro | TARGET | 6 |
| 329.5 | Google Pixel 2 | TARGET | 7 |
| 119.395 | Chromebook | WALMART | 8 |
لاحظ أن بإمكاننا استخدام مسميات مستعارة للجداول Alias باستخدام AS لكي يظهر العمود بمسمى جديد. لكن هذا لا يغير شيء باسم العمود الأصلي
WHERE
WHERE تُمكنا من تحديد شروط معينة للبيانات. مثلاً، إذا أردنا إيجاد فقط المنتجات أقل من $500:
sql_expr = """
SELECT *
FROM prices
WHERE price < 500
"""
pd.read_sql(sql_expr, sqlite_engine)
| price | product | retailer | |
|---|---|---|---|
| 200 | iPod | Best Buy | 0 |
| 450 | iPad | Amazon | 1 |
| 24.87 | Battery pack | Amazon | 2 |
| 249.99 | Chromebook | Amazon | 3 |
| 215 | iPod | Target | 4 |
| 238.79 | Chromebook | Walmart | 5 |
يمكننا أيضا استخدام AND، OR و NOT لتحديد استعلامنا بشكل أدق. مثلاً، للبحث عن منتجات Amazon والتي لا تحتوي على Battery pack وسعرها أقل من $300، نكتب الاستعلام التالي:
sql_expr = """
SELECT *
FROM prices
WHERE retailer = 'Amazon'
AND NOT product = 'Battery pack'
AND price < 300
"""
pd.read_sql(sql_expr, sqlite_engine)
| price | product | retailer | |
|---|---|---|---|
| 249.99 | Chromebook | Amazon | 0 |
ولكتابة نفس الأمر في بانداز:
prices[(prices['retailer'] == 'Amazon')
& ~(prices['product'] == 'Battery pack')
& (prices['price'] <= 300)]
| price | product | retailer | |
|---|---|---|---|
| 249.99 | Chromebook | Amazon | 4 |
نلاحظ هناك وجود فرق يجب التنبيه عنه، الرقم التسلسلي للمنتجي Chromebook في استعلام SQL كان 0، ولكن في استعلام بايثون 4. هذا لأن استعلامات SQL تقوم دائماً بعرض البيانات في جدول جديد وبأرقام تسلسليه جديده تبدأ من 0، ولكن في بانداز تقوم بعرض جزء من ال DataFrame مع استخدام نفس أرقام التسلسل. يمكننا استخدام الدالة pd.DataFrame.reset_index لإعادة تعين الأرقام التسلسلية في بانداز
دوال الجمع
حتى الآن، تعاملنا مع بيانات موجودة في الجداول، يعني ذلك، كل النتائج التي ظهرت سابقاً هي أجزاء من المدخلات في الجداول. ولكن لتطبيق تحليل للبيانات، نحتاج للقيام ببعض عمليات التجميع على بياناتنا. في SQL، يطلق عليها دوال التجميع Aggregate Functions.
لنوجد قيمة متوسط أسعار جميع المنتجات في جدول prices:
sql_expr = """
SELECT AVG(price) AS avg_price
FROM prices
"""
pd.read_sql(sql_expr, sqlite_engine)
| avg_price | |
|---|---|
| 395.072222 | 0 |
وفي بانداز نكتبها:
prices['price'].mean()
395.0722222222222
قائمة كاملة بجميع دوال التجميع في PostgreSQL هنا. على الرقم من أننا نستخدمها كأداة أساسيه للتعامل مع SQL في هذه المادة، تذكر أن هناك أنواع مختلفة من SQL مثل MySQL، SQLite وغيرها التي تستخدم أسماء مختلفة للدوال وبعض الأحيان تحتوي على دوال مختلفة.
GROUP BY و HAVING
باستخدام دوال التجميع، يمكننا القيام باستعلامات مُعقده. لاستخدام دوال تجميع سهله التعامل، يمكننا تجربة التالية:
GROUP BYتستقبل أسماء أعمدة وتقوم بجمعها كما في دالة pd.DataFrame.groupby في بانداز.HAVINGتعمل بشكل مشابه لWHERE1، ولكن تستخدم فقط على البيانات الناتجة ممن الدوال المجمعه. (ملاحظة: لاستخدامHAVING، يجب أن تكون مسبوقة بGROUP BY)
**ملاحظة مهمة: ** عند استخدام GROUP BY، يجب أن تكون جميع الأعمدة في SELECT موجودة في GROUP BY أو تكون دالة تجميع مطبقه عليها.
يمكننا استخدام الاستعلام التالي لإيجاد أعلى سعر لكل متجر:
sql_expr = """
SELECT retailer, MAX(price) as max_price
FROM prices
GROUP BY retailer
"""
pd.read_sql(sql_expr, sqlite_engine)
| max_price | retailer | |
|---|---|---|
| 450 | Amazon | 0 |
| 719 | Best Buy | 1 |
| 799 | Target | 2 |
| 238.79 | Walmart | 3 |
لنقل أن لدينا عميل ذو ذوق عالي ويريد فقط تلك المتاجر التي تبيع منتجات بسعر أعلى من $700. لاحظ أن يجب علينا استخدام HAVING لإيجاد النتيجة من عمود تم تجميعه؛ لا يمكننا استخدام WHERE لفلترة نتائج عمود مُجَمع. لإيجاد قائمة بالمتاجر التي تبيع المنتجات المفضلة لعميلنا نقوم بالتالي:
sql_expr = """
SELECT retailer, MAX(price) as max_price
FROM prices
GROUP BY retailer
HAVING max_price > 700
"""
pd.read_sql(sql_expr, sqlite_engine)
| max_price | retailer | |
|---|---|---|
| 719 | Best Buy | 0 |
| 799 | Target | 1 |
وللمقارنة مع بايثون:
max_prices = prices.groupby('retailer').max()
max_prices.loc[max_prices['price'] > 700, ['price']]
| price | |
|---|---|
| retailer | |
| 719 | Best Buy |
| 799 | Target |
ORDER BY و LIMIT
تُمكنا الأوامر التالية من التحكم بكيفية عرض البيانات:
ORDER BYتساعدنا على عرض البيانات بشكل مُرتب بِنَاءًا على القيم داخل العمود بشكل تلقائي،ORDER BYتستخدم الترتيب التصاعديASCولكن يمكننا عكسها وعرض البيانات بشكل تنازلي باستخدامDESC.LIMITتسمح لنا بتحديد كم من البيانات نعرض.
لنقم بعرض أقل المنتجات سعراً في جدول prices:
sql_expr = """
SELECT *
FROM prices
ORDER BY price ASC
LIMIT 3
"""
pd.read_sql(sql_expr, sqlite_engine)
| price | product | retailer | |
|---|---|---|---|
| 24.87 | Battery pack | Amazon | 0 |
| 200 | iPod | Best Buy | 1 |
| 215 | iPod | Target | 2 |
لاحظ أننا لم نحتاج لإضافة ASC لأن ORDER BY تجلب لنا البيانات بترتيب تصاعدي بشكل تلقائي. للمقارنة مع بانداز:
prices.sort_values('price').head(3)
| price | product | retailer | |
|---|---|---|---|
| 24.87 | Battery pack | Amazon | 3 |
| 200 | iPod | Best Buy | 1 |
| 215 | iPod | Target | 5 |
مره أخرى، نلاحظ أن الأرقام التسلسليه غير مرتبه في بانداز. كما في السابق، بانداز تقوم بعرض DataFrame كما هي، عل عكس SQL التي تنشأ جدول جديد عند كُل استعلام.
ترتيب الأوامر في SQL
تطبق الأوامر في SQL بشكل مُرتب. للأسف، أن الترتيب مختلف عن ما يظهر في كتابة الاستعلام. ترتيب الأوامر كالتالي:
FROM: جدول أو أكثر من جدول.WHERE: تطبيق شروط على الأسطر.GROUP BY: التجميع.HAVING: تطبيق الشروط على التجميع.SELECT: اختيار الأعمدة
ملاحظة في WHERE و HAVING: بما أن WHERE تُطبق قبل GROUP BY، فإن WHERE لا تفيدنا عندما نقوم بالتجميع. لذا، للتعامل مع بيانات مجمعه نستخدم HAVING.
ملخص SQL
في هذا الجزء قمنا بشرح طريقة كتابة استعلامات SQL واهم الأوامر لإجراء تحليل للبيانات باستخدام أنظمة قواعد البيانات العلائقية.
الربط في SQL
في بانداز يمكننا استخدام الدالة pd.merge لجمع جدولين معاً يحتويان على قيم متشابهه في أحد الأعمدة. مثلاً:
pd.merge(table1, table2, on='common_column')
في هذا الجزء، سنتعلم الجمع فيه SQL والذي يفيدنا في جمع أكثر من جدول في قواعد البيانات العلائقية.
لنفرض مثلاً أننا متجر لمنتجات القطط ولدينا قاعدة بيانات بالقطط التي في متجرنا. لدينا جدولين مختلفين: names و colors. جدول names يحتوي على الأعمدة:
cat_id: رقم مميز لكل قط.name: اسم القط.
جدول colors يحتوي على الأعمدة:
cat_id: رقم مميز لكل قط.color: لون كل قط.
لاحظ وجود قيم مفقوده في كل جدول. القيمة 3 في العمود cat_id مفقوده من جدول names، والقيمة 4 من عمود cat_id مفقوده في جدول colors
| Names Table | Colors Table | ||||||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
|
|
لإيجاد لون القط ذو الاسم Apricot، يجب علينا استخدام معلومه من جدولين. يمكننا ربط الجدولين باستخدام العمود cat_id، ويكون لدينا جدول جديد يحتوي على name و color.
الربط
الربط بين عدة جداول باستخدام قيم في أعمدتها.
يوجد أربع أنواع من الربط: الربط الداخلي Inner Join, الربط الخارجي Outer Join أو الكامل Full Join, الربط اليميني Right Join والربط اليساري Left Join. بالرغم بأن جميعها تربط بين الجداول وتقوم بجمعها، إلا أن كل نوع يعامل القيم بطريقة مختلفة.
Inner Join
تعريف: في الربط الداخلي، الجدول النهائي يحتوي على القيم المتشابهة في الجدولين المربوطين معاً.
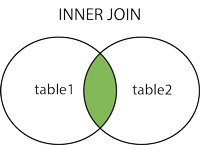
مثال: نريد الربط بين جدولي names و colors لجمع كل قطه مع لونها. بما أن كلا الجدولين يحتويان على العمود cat_id وهو رقم مميز لكل قط، يمكننا استخدام الربط الداخلي باستخدام العمود cat_id.
SQL: لكتابة الربط الداخلي في SQL، نقوم بتعديل FROM بإضافة INNER JOIN عليها:
SELECT ...
FROM <TABLE_1>
INNER JOIN <TABLE_2>
ON <...>
مثلاً:
SELECT *
FROM names AS N
INNER JOIN colors AS C
ON N.cat_id = C.cat_id;
| color | cat_id | name | cat_id | |
|---|---|---|---|---|
| orange | 0 | Apricot | 0 | 0 |
| black | 1 | Boots | 1 | 1 |
| calico | 2 | Cally | 2 | 2 |
يمكنك التحقق من أن كل اسم قطه حصل على لونها الصحيح. لاحظ، القطة صاحبة cat_id رقم 3 و 4 لم يتم جمعها في الجدول النهائي لأن جدول colors لا يحتوي على سطر بقيمة cat_id تساوي 4 و جدول names لا يحتوي على سطر cat_id بقيمة 3. في الدمج الداخلي، إذا لم يكون هناك قيم متشابهه في كلا الجدولين، لن يتم ضم القيمة في النتيجه النهائية.
لنفترض أن لدينا DataFrame بإسم names وأخرى بإسم colors، يمكننا كتابة الدمج الداخلي في بانداز بالطريقة التالية:
pd.merge(names, colors, how='inner', on='cat_id')
Full/Outer Join
تعريف: في الربط الكامل/الخارجي، كل القيم في كلا الجدولين يتم أضافتها في الجدول النهائي. إذا كانت القيمة موجودة في جدول دون الآخر، فيتم تعويضها ب NULL.
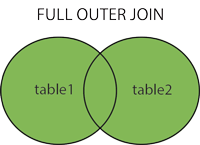
مثال: كما في السابق، نريد الربط بين الجدول names و colors لإعطاء كل قطه لونها. هذه المرة، نريد إظهار جميع القيم في الجداول حتى لو لا يجود لها قيم مُطابقه.
SQL: لكتابة الربط الكامل/الخارجي في SQL، نقوم بتعديل FROM بإضافة FULL JOIN عليها:
SELECT ...
FROM <TABLE_1>
FULL JOIN <TABLE_2>
ON <...>
مثلاً:
SELECT name, color
FROM names N
FULL JOIN colors C
ON N.cat_id = C.cat_id;
| color | name | cat_id |
|---|---|---|
| orange | Apricot | 0 |
| black | Boots | 1 |
| calico | Cally | 2 |
| white | NULL | 3 |
| NULL | Eugene | 4 |
لاحظ في النتيجة النهاية ظهور القيم 3 و 4 في عمود cat_id. إذا كانت أحد القيم تظهر في جدول دون الآخر، فيتم إضافتها للجدول النهائي مع القيمة NULL بدلاً من القيم المفقودة.
في بانداز نكتبها كالتالي:
pd.merge(names, colors, how='outer', on='cat_id')
Left Join
تعريف: جميع القيم في الجدول على اليسار يتم ربطها في الجدول النهائي. إذا كانت قيمه في الجدول اليساري لا توجد لها مطابق على الجدول الآخر، يتم تعويض قيمتها المفقودة ب NULL.
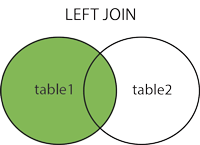
مثال: نربط الجدولان names و colors لإظهار ألوان القطط. هنا، نريد إظهار جميع أسماء القطط حتى لو لم يكن لها لون في الجدول colors.
SQL: لكتابة الربط اليساري في SQL، نقوم بتعديل FROM بإضافة LEFT JOIN عليها:
SELECT ...
FROM <TABLE_1>
LEFT JOIN <TABLE_2>
ON <...>
مثلاً:
SELECT name, color
FROM names N
LEFT JOIN colors C
ON N.cat_id = C.cat_id;
| color | name | cat_id |
|---|---|---|
| orange | Apricot | 0 |
| black | Boots | 1 |
| calico | Cally | 2 |
| NULL | Eugene | 4 |
لاحظ أن الجدول النهائي يحتوي على جميع أسماء القطط. ثلاثة من القيم cat_id في جدول names تحتوي على قيم بنفس ال cat_id في جدول colors وواحده لا تحتوي على قيمه مطابقة (Eugene). القط الذي لا يوجد له لون تم تعويض قيمته ب NULL.
في بانداز نكتب الاستعلام كالتالي:
pd.merge(names, colors, how='left', on='cat_id')
Right Join
تعريف: جميع القيم في الجدول على اليمين يتم ربطها في الجدول النهائي. إذا كانت قيمه في الجدول اليميني لا توجد لها مطابق على الجدول الآخر، يتم تعويض قيمتها المفقودة ب NULL.
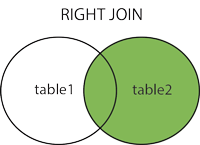
مثال: الجدولان names و colors، نريد ربطها كل قط بلونه. لكن، نريد إظهار جميع ألوان القطط حتى لو لم يكن لها أسماء.
SQL: لكتابة الربط اليمين في SQL، نقوم بتعديل FROM بإضافة RIGHT JOIN عليها:
SELECT ...
FROM <TABLE_1>
RIGHT JOIN <TABLE_2>
ON <...>
مثلاً:
ELECT name, color
FROM names N
RIGHT JOIN colors C
ON N.cat_id = C.cat_id;
| color | name | cat_id |
|---|---|---|
| orange | Apricot | 0 |
| black | Boots | 1 |
| calico | Cally | 2 |
| white | NULL | 3 |
هذه المرة، الجدول النهائي يظهر جميع الألوان. ثلاثة من القيم في العمود cat_id بجدول colors لديها مطابق في عمود cat_id بجدول names وقيمه واحد لم تجد مطابق (white). اللون الذي لم يجد له اسم مطابق سيعوض بالقيمة NULL.
في بانداز:
pd.merge(names, colors, how='right', on='cat_id')
Implicit Inner Join
عادةً توجد أكثر من طريقه لإيجاد نتيجة معينة في SQL تماما كما في بايثون يوجد أكثر من طريقه لحل مشاكل. سنوضح طريقه أخرى لكتابة استعلامات Inner Join تسمى Implicit Join.
كتبنا سابقاً الربط الداخلي التالي:
SELECT *
FROM names AS N
INNER JOIN colors AS C
ON N.cat_id = C.cat_id;
الطريقة الأخرى Implicit لكتابة هذا الأمر يكون شكلها مختلف ودون INNER JOIN. لاحظ أن FORM يستخدم فيها الفواصل بين جدولين والشرط WHERE يحدد شروط الربط:
SELECT *
FROM names AS N, colors AS C
WHERE N.cat_id = C.cat_id;
عند استخدام أكثر من جدول في FORM، تقوم SQL بإنشاء جدول يحتوي على كل سطر بكلا الجدولين، مثلاً:
sql_expr = """
SELECT *
FROM names N, colors C
"""
pd.read_sql(sql_expr, sqlite_engine)
| color | cat_id | name | cat_id | |
|---|---|---|---|---|
| orange | 0 | Apricot | 0 | 0 |
| black | 1 | Apricot | 0 | 1 |
| calico | 2 | Apricot | 0 | 2 |
| white | 3 | Apricot | 0 | 3 |
| orange | 0 | Boots | 1 | 4 |
| black | 1 | Boots | 1 | 5 |
| calico | 2 | Boots | 1 | 6 |
| white | 3 | Boots | 1 | 7 |
| orange | 0 | Cally | 2 | 8 |
| black | 1 | Cally | 2 | 9 |
| calico | 2 | Cally | 2 | 10 |
| white | 3 | Cally | 2 | 11 |
| orange | 0 | Eugene | 4 | 12 |
| black | 1 | Eugene | 4 | 13 |
| calico | 2 | Eugene | 4 | 14 |
| white | 3 | Eugene | 4 | 15 |
يطلق على هذه العملية بالضرب الديكارتي Cartesian product، كل سطر في الجدول الأول يربط بكل سطر في الجدول الثاني. لاحظ أن الكثير من الأسطر تحتوي على ألوان قطط لا تتطابق مع أسمائها. الشرط الإضافي في WHERE يطبق الربط ويفلتر القيم التي لا تتطابق في عمود cat_id:
SELECT *
FROM names AS N, colors AS C
WHERE N.cat_id = C.cat_id;
| color | cat_id | name | cat_id | |
|---|---|---|---|---|
| orange | 0 | Apricot | 0 | 0 |
| black | 1 | Boots | 1 | 1 |
| calico | 2 | Cally | 2 | 2 |
ربط أكثر من جدول
لربط أكثر من جدول، نضيف على المتغير FROM أوامر الربط JOIN. مثلاً، جدول الأعمار للقطط:
| cat_id | age |
|---|---|
| 0 | 4 |
| 1 | 3 |
| 2 | 9 |
| 4 | 20 |
لإجراء عملية الربط الداخلي على الجداول neams، colors و ages نكتب التالي:
sql_expr = """
SELECT name, color, age
FROM names n
INNER JOIN colors c ON n.cat_id = c.cat_id
INNER JOIN ages a ON n.cat_id = a.cat_id;
"""
pd.read_sql(sql_expr, sqlite_engine)
| age | color | name | |
|---|---|---|---|
| 4 | orange | Apricot | 0 |
| 3 | black | Boots | 1 |
| 9 | calico | Cally | 2 |
ملخص الربط
قمنا بعرض الأربع أنواع الأساسيه للربط في SQL: الربط الداخلي، الكامل، اليميني واليساري. نستخدم جميع الأنواع في الربط للقيام بعمليات الربط بين الجداول المنفصله التي تربطها علاقات، كل عملية ربط لديها طرق مختلفة للربط بين القيم.