مبادئ وتقنيات علم البيانات
الفصل الخامس: تنظيف البيانات
فهرس الفصل:
مقدمة
تأتي البيانات بعدة أشكال وتتنوع من حيث فائدتها في التحليل. رغم أننا نسعى أن تكون جميع البيانات على شكل جدول وكل قيمه تم إدخالها بشكل صحيح ودقيق، ولكن يجب علينا التحقق بشكل دقيق عن المشاكل التي قد تقودنا لنتائج غير صحيحه.
المصطلح تنظيف البيانات يطلق على خطوة التحقق من البيانات واتخاذ قرارات عن كيفية إصلاح الأخطاء وتعويض البيانات المفقودة. سنناقش أكثر المشاكل الشائعة في البيانات ونشرحها بشكل أوضح.
تنظيف البيانات له بعض القيود. مثلاً، لا يوجد تنظيف بإمكانه تحسين عينات تم أخذها بشكل متحيز. قبل البدء بمشوار تنظيف البيانات الذي عاده ما يكون طويلاً، يجب ان نتأكد ان بياناتنا تم جمعها بشكل دقيق ودون تحيز. في ذلك الحين يمكننا بدأ التحقق من البيانات وتنظيفها للتخلص من المشاكل في أنواع البيانات أو طرق الإدخال.
سنقوم بشرح طُرق لتنظيف البيانات وسنستخدم بيانات شرطة مدينة بيركلي.
نظره على بيانات شرطة مدينة بيركلي
سنستخدم بيانات شرطة مدينة بيركلي المنشورة للعامة لشرح طرق تنظيف البيانات. يمكن تحميل بيانات المكالمات من هنا، وبيانات الإيقافات من هنا.
روابط أخرى لتحميل البيانات:
سنستخدم الأمر ls مع -lh لعرض معلومات أكثر عن الملفات:
!ls -lh data/
total 13936
-rw-r--r--@ 1 sam staff 979K Aug 29 14:41 Berkeley_PD_-_Calls_for_Service.csv
-rw-r--r--@ 1 sam staff 81B Aug 29 14:28 cvdow.csv
-rw-r--r--@ 1 sam staff 5.8M Aug 29 14:41 stops.json
يظهر لنا الأمر السابق الملفات في المجلد وأحجامها. الأمر مهم لأنه يبين لنا أن الملفات صغيرة الحجم ويمكن تحميلها على ذاكرة حاسبنا. قاعدة عامه، يمكن تحميل الملفات بشكل آمن عندما يكون حجمها حوالي ربع حجم الذاكرة في الحاسب. مثلاً، إذا كان جهازنا يحتوي على 4 ج.ب. من الذاكرة العشوائية، يمكننا تحميل ملف CSV بحجم 1 ج.ب في بانداز. ليتحمل حاسبنا ملفات بحجم أكبر يجب علينا استخدام أدوات خاصة وسنتحدث لاحقاً عنها في هذا الكتاب.
لاحظ استخدامنا لعلامة التعجب قبل ls. هذا يخبر جوبتر أن الكود البرمجي التالي خاص بمترجم الشيل، وليس بايثون. مثال آخر:
# الامر `wc` يظهر عدد الاسطر في كل ملف.
# يمكن ان نلاحظ ان ملف `stops.json` يحتوي على عدد (29852) سطر.
!wc -l data/*
16497 data/Berkeley_PD_-_Calls_for_Service.csv
8 data/cvdow.csv
29852 data/stops.json
46357 total
تنظيف بيانات المكالمات
فهم توليد البيانات
سنقوم بطرح بعض الأسئلة التي يجب أن تتحقق منها في جميع بياناتك قبل البدء بتنظيفها ومعالجتها. هذه الأسئلة عن كيف تم توليد وإنشاء هذه البيانات. في هذه الخطوة، تنظيف البيانات لن يساعدنا على حل المشاكل التي حصلت أثناء إنشاء البيانات.
على ماذا تحتوي البيانات؟ الموقع الذي تم أخذ بيانات المكالمات منه يذكر أن “الجرائم/الحوادث (وليس تقارير الجرائم) التي حدثت في ال180 يوم السابقة”. مزيد من القراءة في الموقع أوضحت التالي “ليس جميع المكالمات التي طلبت خدمات الشرطة تم إضافتها (مثال لأحد الحالات التي تمت ولم يتم إضافتها: حالة عض حيوان لشخص)”.
موقع بيانات الإيقافات يوضح أن البيانات تحتوي على جميع “السيارات المحتجزة (بما فيها الدراجات الهوائية) واعتقالات المشاة (بحد أعلى خمسة أشخاص)” منذ 26 يناير 2015.
هل البيانات تعداد / إحصاء على السكان؟ يعتمد ذلك على هدفنا من تحليل البيانات. مثلاً، إذا كنا مهتمين بمعرفة المكالمات التي طلبت فيها الخدمات لآخر 180 يوم للحوادث والجرائم، فإن بيانات المكالمات تعتبر بيانات إحصائية للمكالمات التي تمت آخر 180 يوم من قبل السكان. ولكن إذا أردنا المكالمات لطلب خدمات الشرطة للعشر سنوات السابقة، فإن البيانات ليست مناسبة كونها تحتوي على بيانات آخر 180 يوم فقط. يمكننا ذكر نفس الكلام على بيانات الإيقافات لأن البيانات تم جمعها ابتداء من 26 يناير 2015.
إذا كانت البيانات تُشكل عينه، هل هي عينة الاحتمالات؟ البيانات لا تمثل عينة الاحتمالات لأنها لا تظهر أي عشوائية في طريقة جمع البيانات. لدينا بيانات كاملة لفترة معينة فقط وليس لفترات أخرى.
هل هناك قيود ستجبرنا عليه البيانات في نتائجنا؟ رغم أننا سنسأل هذا السؤال بعد كل خطوه من خطواتنا، يمكننا ملاحظة أن بياناتنا تظهر لنا بعض القيود. أهم القيود التي تظهرها لنا هي أننا لا يمكننا القيام بأي تقديرات غير متحيزة للفترات التي لم يتم تسجيلها في البيانات.
تنظيف البيانات
لنبدأ الآن بتنظيف بيانات المكالمات. الأمر head يظهر لنا أول خمس أسطر في الملف:
!head data/Berkeley_PD_-_Calls_for_Service.csv
CASENO,OFFENSE,EVENTDT,EVENTTM,CVLEGEND,CVDOW,InDbDate,Block_Location,BLKADDR,City,State
17091420,BURGLARY AUTO,07/23/2017 12:00:00 AM,06:00,BURGLARY - VEHICLE,0,08/29/2017 08:28:05 AM,"2500 LE CONTE AVE
Berkeley, CA
(37.876965, -122.260544)",2500 LE CONTE AVE,Berkeley,CA
17020462,THEFT FROM PERSON,04/13/2017 12:00:00 AM,08:45,LARCENY,4,08/29/2017 08:28:00 AM,"2200 SHATTUCK AVE
Berkeley, CA
(37.869363, -122.268028)",2200 SHATTUCK AVE,Berkeley,CA
17050275,BURGLARY AUTO,08/24/2017 12:00:00 AM,18:30,BURGLARY - VEHICLE,4,08/29/2017 08:28:06 AM,"200 UNIVERSITY AVE
Berkeley, CA
(37.865491, -122.310065)",200 UNIVERSITY AVE,Berkeley,CA
يظهر أن الملف من النوع CSV، ولكن من الصعب معرفة ما إذا كان جميع محتوى الملف منسق بطريقه صحيحه. يمكننا استخدام الدالة pd.read_csv لقراءة الملف ك DataFrame. إذا أظهر الأمر pd.read_csv أخطاء، فيجب علينا البحث بشكل أعمق وحل المشكلة يدوياً. لحسن الحظ، قامت الدالة بقراءة الملف بشكل صحيح على شكل DataFrame:
import pandas as pd
calls = pd.read_csv('data/Berkeley_PD_-_Calls_for_Service.csv')
calls
| State | City | BLKADDR | Block_Location | … | EVENTTM | EVENTDT | OFFENSE | CASENO | |
|---|---|---|---|---|---|---|---|---|---|
| CA | Berkeley | 2500 LE CONTE AVE | 2500 LE CONTE AVE\nBerkeley, CA\n(37.876965, -… | … | 06:00 | 07/23/2017 12:00:00 AM | BURGLARY AUTO | 17091420 | 0 |
| CA | Berkeley | 2200 SHATTUCK AVE | 2200 SHATTUCK AVE\nBerkeley, CA\n(37.869363, -… | … | 08:45 | 04/13/2017 12:00:00 AM | THEFT FROM PERSON | 17020462 | 1 |
| CA | Berkeley | 200 UNIVERSITY AVE | 200 UNIVERSITY AVE\nBerkeley, CA\n(37.865491, … | … | 18:30 | 08/24/2017 12:00:00 AM | BURGLARY AUTO | 17050275 | 2 |
| … | … | … | … | … | … | … | … | … | … |
| CA | Berkeley | 1600 FAIRVIEW ST | 1600 FAIRVIEW ST\nBerkeley, CA\n(37.850001, -1… | … | 12:22 | 04/01/2017 12:00:00 | DISTURBANCE | 17018126 | 5505 |
| CA | Berkeley | 2000 DELAWARE ST | 2000 DELAWARE ST\nBerkeley, CA\n(37.874489, -1… | … | 12:00 | 04/01/2017 12:00:00 | THEFT MISD. (UNDER $950) | 17090665 | 5506 |
| CA | Berkeley | 2400 TELEGRAPH AVE | 2400 TELEGRAPH AVE\nBerkeley, CA\n(37.866761, … | … | 20:02 | 08/22/2017 12:00:00 AM | SEXUAL ASSAULT MISD. | 17049700 | 5507 |
5508 rows × 11 columns
يمكننا كتابة دالة تقوم بإظهار أجزاء من البيانات:
import numpy as np
import matplotlib.pyplot as plt
import pandas as pd
import seaborn as sns
%matplotlib inline
import ipywidgets as widgets
from ipywidgets import interact, interactive, fixed, interact_manual
def df_interact(df):
def peek(row=0, col=0):
return df.iloc[row:row + 5, col:col + 6]
interact(peek, row=(0, len(df), 5), col=(0, len(df.columns) - 6))
print('({} rows, {} columns) total'.format(df.shape[0], df.shape[1]))
df_interact(calls)
الكود البرمجي السابق يُنتِج لنا جدول تفاعلي كما في الصورة أدناه، يحتوي بشكل تلقائي على ال6 أسطر الأولى و أول 6 أعمدة. عند تحريك أي من الشريطين تظهر لنا أسطر / أعمدة مختلفة بناءًا على رقم السطر الذي اخترناه ورقم الأعمدة. تذكر دائماً أنه الترقيم في الجداول / بايثون يبدأ من 0.
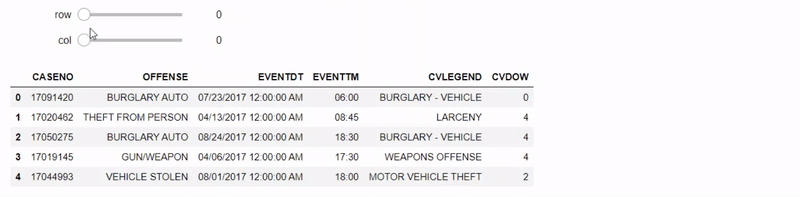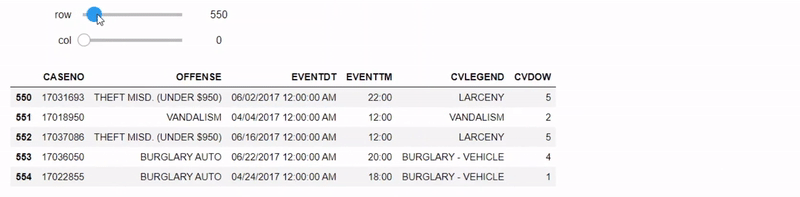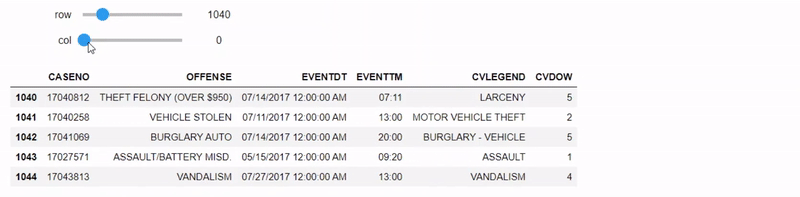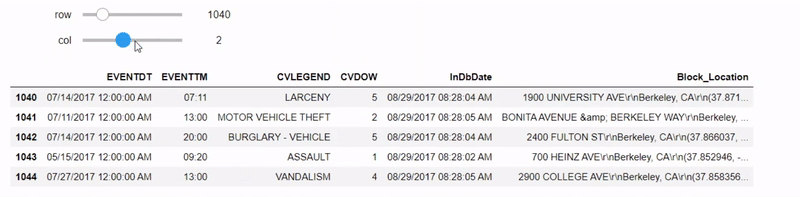
(5508 rows, 11 columns) total
بناءًا على النتائج في الأعلى، تبدو البيانات مرتبه بشكل مناسب بما ان الأعمدة مُسماه بشكل صحيح والبيانات في كل عمود مدخله بشكل متناسق. ماذا يحتوي كل عمود؟ يمكننا التحقق من ذلك بموقع البيانات:
| النوع | الوصف | العمود |
|---|---|---|
| رقم | رقم القضية | CASENO |
| نص | نوع المخالفة | OFFENSE |
| تاريخ + وقت | تاريخ الحدث | EVENTDT |
| نص | وقت الحدث | EVENTTM |
| نص | تفاصيل الحدث | CVLEGEND |
| رقم | أي يوم بالأسبوع حدثت فيه المخالفة | CVDOW |
| تاريخ + وقت | تاريخ ووقت تحديث المخالفة في قاعدة البيانات | InDbDate |
| عنوان | عنوان المخالفه | Block_Location |
| نص | BLKADDR | |
| نص | City | |
| نص | State |
قد تبدو البيانات سهلة التحليل. ولكن قبل البدء بذلك، يجب أن نجيب عن الأسئلة التالية:
- هل توجد بيانات مفقوده؟ السؤال مهم لأن البيانات المفقودة قد تكون لعدة أسباب. مثلاً، عناوين مفقوده قد يكون حذفها بسبب حماية خصوصية الأشخاص، أو أن أحد المباشرين لهذه المخالفة رفض الإجابة على هذا السؤال، أو بسبب حدوث مشاكل في جهاز التسجيل.
- هل توجد أي بيانات مفقوده تم تعبئتها؟ ( مثلاً كتابة رقم 999 لعمر مجهول أو 12:00 صباحاً لتاريخ مجهول)؟ بالتأكيد سيأثر ذلك على تحليلنا إذا تجاهلناها.
- أي جزء من البيانات أدخلت بواسطة أشخاص حقيقيين؟ كما سنرى بعد قليل، البيانات التي يتم ادخالها من البشر تحتوي على الكثير من التناقضات والأخطاء الإملائيه.
رغم أن هناك الكثير من المشاكل التي يجب أن نتحقق منها، هذه المشاكل الثلاثة هي الأكثر تكراراً في جميع البيانات. يمكنك مراجعة Quartz لاستعراض قائمة من المشاكل التي يحتاج للتحقق منها في البيانات قبل البدء بالتحليل.
هل توجد بيانات مفقوده؟
هذه الخطوة سهله التحقق في بانداز عن طريق الكود البرمجي التالي:
# ستظهر لنا الأسطر التي تحتوي على الاقل على قيمه واحده مفقوده
null_rows = calls.isnull().any(axis=1)
calls[null_rows]
| State | City | BLKADDR | Block_Location | … | EVENTTM | EVENTDT | OFFENSE | CASENO | |
|---|---|---|---|---|---|---|---|---|---|
| CA | Berkeley | NaN | Berkeley, CA\n(37.869058, -122.270455) | … | 22:00 | 03/16/2017 12:00:00 AM | BURGLARY AUTO | 17014831 | 116 |
| CA | Berkeley | NaN | Berkeley, CA\n(37.869058, -122.270455) | … | 16:00 | 07/20/2017 12:00:00 AM | BURGLARY AUTO | 17042511 | 478 |
| CA | Berkeley | NaN | Berkeley, CA\n(37.869058, -122.270455) | … | 21:00 | 04/22/2017 12:00:00 AM | VEHICLE STOLEN | 17022572 | 486 |
| … | … | … | … | … | … | … | … | … | … |
| CA | Berkeley | NaN | Berkeley, CA\n(37.869058, -122.270455) | … | 08:00 | 07/01/2017 12:00:00 | VANDALISM | 17091287 | 4945 |
| CA | Berkeley | NaN | Berkeley, CA\n(37.869058, -122.270455) | … | 15:00 | 06/30/2017 12:00:00 AM | BURGLARY RESIDENTIAL | 17038382 | 4947 |
| CA | Berkeley | NaN | Berkeley, CA\n(37.869058, -122.270455) | … | 23:30 | 08/15/2017 12:00:00 AM | VANDALISM | 17091632 | 5167 |
27 rows × 11 columns
يظهر لنا 27 سطرًا لا تحتوي على عناوين في العمود BLKADDR. لسوء الحظ، لا يظهر لنا في شرح البيانات اي معلومه عن طريقة حفظ معلومات العنوان. نعرف أن جميع البيانات لأحداث تمت في مدينة بيركلي، لذا يمكننا الافتراض ان جميع المكالمات كانت لعناوين في مكان ما في بيركلي.
هل توجد أي بيانات مفقوده تم تعبئتها؟
من النتيجه السابقه نلاحظ ان العمود Block_Location يحتوي على القيمه Berkeley, CA اذا كان القيمه في العمود BLKADDR مفقوده.
أيضاً، التحقق من الجدول اظهر لنا ان العمود EVENTDT يحتوي على التاريخ بشكل صحيح ولكن في كل الأسطر تم تسجيل الوقت 12:00:00AM ، الوقت الحقيقي في العمود EVENTTM. لنتحقق من ما اكتشفناه:
# اظهار اول سبع اسطر
calls.head(7)
| State | City | BLKADDR | Block_Location | … | EVENTTM | EVENTDT | OFFENSE | CASENO | |
|---|---|---|---|---|---|---|---|---|---|
| CA | Berkeley | 2500 LE CONTE AVE | 2500 LE CONTE AVE\nBerkeley, CA\n(37.876965, -… | … | 06:00 | 07/23/2017 12:00:00 AM | BURGLARY AUTO | 17091420 | 0 |
| CA | Berkeley | 2200 SHATTUCK AVE | 2200 SHATTUCK AVE\nBerkeley, CA\n(37.869363, -… | … | 08:45 | 04/13/2017 12:00:00 AM | THEFT FROM PERSON | 17020462 | 1 |
| CA | Berkeley | 200 UNIVERSITY AVE | 200 UNIVERSITY AVE\nBerkeley, CA\n(37.865491, … | … | 18:30 | 08/24/2017 12:00:00 AM | BURGLARY AUTO | 17050275 | 2 |
| CA | Berkeley | 1900 SEVENTH ST | 1900 SEVENTH ST\nBerkeley, CA\n(37.869318, -12… | … | 17:30 | 04/06/2017 0:00 | GUN/WEAPON | 17019145 | 3 |
| CA | Berkeley | 100 PARKSIDE DR | 100 PARKSIDE DR\nBerkeley, CA\n(37.854247, -12… | … | 18:00 | 08/01/2017 0:00 | VEHICLE STOLEN | 17044993 | 4 |
| CA | Berkeley | 1500 PRINCE ST | 1500 PRINCE ST\nBerkeley, CA\n(37.851503, -122… | … | 12:00 | 06/28/2017 12:00:00 AM | BURGLARY RESIDENTIAL | 17037319 | 5 |
| CA | Berkeley | 300 MENLO PL | 300 MENLO PL\nBerkeley, CA\n | … | 08:45 | 05/30/2017 12:00:00 AM | BURGLARY RESIDENTIAL | 17030791 | 6 |
7 rows × 11 columns
كخطوة تنظيف، نريد أن نجمع الأعمدة EVENTDT و EVENTTM ليحتوي على التاريخ والوقت في عمود واحد. إذا قمنا بكتابة دالة تستقبل DataFrame وتنشأ أخرى، فيمكننا لاحقنا استخدام pd.pipe لتطبيق ذلك على جميع القيم: 📝
def combine_event_datetimes(calls):
combined = pd.to_datetime(
# جمع التاريخ والوقت على شكل نص
calls['EVENTDT'].str[:10] + ' ' + calls['EVENTTM'],
infer_datetime_format=True,
)
return calls.assign(EVENTDTTM=combined)
# لعرض النتائج قبل التعديل على ال DataFrame
calls.pipe(combine_event_datetimes).head(2)
| EVENTDTTM | State | City | BLKADDR | … | EVENTTM | EVENTDT | OFFENSE | CASENO | |
|---|---|---|---|---|---|---|---|---|---|
| 23/07/2017 06:00:00 | CA | Berkeley | 2500 LE CONTE AVE | … | 06:00 | 07/23/2017 12:00:00 AM | BURGLARY AUTO | 17091420 | 0 |
| 2017-04-13 08:45:00 | CA | Berkeley | 2200 SHATTUCK AVE | … | 08:45 | 04/13/2017 12:00:00 AM | THEFT FROM PERSON | 17020462 | 1 |
2 rows × 12 columns
أي جزء من البيانات أدخلت بواسطة أشخاص حقيقيين؟
يبدو أن الكثير من الأعمدة تم إدخالها بشكل تلقائي بواسطة الآلة، بما في ذلك التاريخ، الوقت، اليوم في الأسبوع، وعنوان الحادثة.
أيضاً، الأعمدة OFFENSE و CVLEGEND يبدو أنها تحتوي على بيانات ثابتة. يمكننا التحقق من القيم المدخلة في كل عمود لنتحقق إن كان هناك أي قيم تحتوي على أخطاء إملائية:
calls['OFFENSE'].unique()
array(['BURGLARY AUTO', 'THEFT FROM PERSON', 'GUN/WEAPON',
'VEHICLE STOLEN', 'BURGLARY RESIDENTIAL', 'VANDALISM',
'DISTURBANCE', 'THEFT MISD. (UNDER $950)', 'THEFT FROM AUTO',
'DOMESTIC VIOLENCE', 'THEFT FELONY (OVER $950)', 'ALCOHOL OFFENSE',
'MISSING JUVENILE', 'ROBBERY', 'IDENTITY THEFT',
'ASSAULT/BATTERY MISD.', '2ND RESPONSE', 'BRANDISHING',
'MISSING ADULT', 'NARCOTICS', 'FRAUD/FORGERY',
'ASSAULT/BATTERY FEL.', 'BURGLARY COMMERCIAL', 'MUNICIPAL CODE',
'ARSON', 'SEXUAL ASSAULT FEL.', 'VEHICLE RECOVERED',
'SEXUAL ASSAULT MISD.', 'KIDNAPPING', 'VICE', 'HOMICIDE'], dtype=object)
calls['CVLEGEND'].unique()
array(['BURGLARY - VEHICLE', 'LARCENY', 'WEAPONS OFFENSE',
'MOTOR VEHICLE THEFT', 'BURGLARY - RESIDENTIAL', 'VANDALISM',
'DISORDERLY CONDUCT', 'LARCENY - FROM VEHICLE', 'FAMILY OFFENSE',
'LIQUOR LAW VIOLATION', 'MISSING PERSON', 'ROBBERY', 'FRAUD',
'ASSAULT', 'NOISE VIOLATION', 'DRUG VIOLATION',
'BURGLARY - COMMERCIAL', 'ALL OTHER OFFENSES', 'ARSON', 'SEX CRIME',
'RECOVERED VEHICLE', 'KIDNAPPING', 'HOMICIDE'], dtype=object)
بما أن كل قيمه يبدو أنها أدخلت بشكل صحيح، لن نحتاج للقيام بأي تعديلات على العمودان.
تحققنا أيضاً من العمود BLKADDR إن كان يحتوي على أي تناقضات ووجدنا أن العناوين أدخلت في بعض المرات على الشكل التالي 2500 LE CONTE AVE كعنوان كامل وفي بعض مرات أخرى سجل العنوان كتقاطع شارعين مثل ALLSTON WAY & FIFTH ST. يشير ذلك أن البيانات أدخلت يدوياً بواسطة أشخاص حقيقيين وليس بشكل آلي، هذا العمود سيكون صعب تحليله. لحسن الحظ يمكننا استخدام بيانات خطوط الطول والعرض Latitude و Longitude بدلاً من العنوان.
calls['BLKADDR'][[0, 5001]]
0 2500 LE CONTE AVE
5001 ALLSTON WAY & FIFTH ST
Name: BLKADDR, dtype: object
لمسات أخيره
تبدو البيانات جاهزة للتحليل الآن. العمود Block_Location يحتوي على نص بالعنوان، خط الطول والعرض. نحتاج لفصل قيمة خط الطول والعرض ليسهل استخدامها:
def split_lat_lon(calls):
return calls.join(
calls['Block_Location']
# الحصول على الإحداثات من النص ( بيانات خط الطول والعرض)
.str.split('\n').str[2]
# حذف الأقواس من النص
.str[1:-1]
# فصل قيم خط الطول والعرض إلى عمودان
.str.split(', ', expand=True)
.rename(columns={0: 'Latitude', 1: 'Longitude'})
)
calls.pipe(split_lat_lon).head(2)
| Longitude | Latitude | State | City | … | CVDOW | EVENTTM | EVENTDT | OFFENSE | CASENO | |
|---|---|---|---|---|---|---|---|---|---|---|
| -122.260544 | 37.876965 | CA | Berkeley | … | 0 | 6:00 | 07/23/2017 12:00:00 AM | BURGLARY AUTO | 17091420 | 0 |
| -122.268028 | 37.869363 | CA | Berkeley | … | 0 | 8:45 | 04/13/2017 12:00:00 AM | THEFT FROM PERSON | 17020462 | 1 |
2 rows × 13 columns
ثم نربط كل رقم في العمود CVDOW مع نص اليوم، سنستخدم الملف cvdow.csv الذي تم تجهيزه مسبقاً، يحتوي الملف على رقم اليوم واليوم كنص مكتوب:
لتحميل الملف: cvdow.csv
day_of_week = pd.read_csv('data/cvdow.csv')
day_of_week
| Day | CVDOW | |
|---|---|---|
| Sunday | 0 | 0 |
| Monday | 1 | 1 |
| Tuesday | 2 | 2 |
| Wednesday | 3 | 3 |
| Thursday | 4 | 4 |
| Friday | 5 | 5 |
| Saturday | 6 | 6 |
نقوم بترجمة العمود CVDOW إلى نص:
def match_weekday(calls):
return calls.merge(day_of_week, on='CVDOW')
calls.pipe(match_weekday).head(2)
| Day | State | City | BLKADDR | … | EVENTTM | EVENTDT | OFFENSE | CASENO | |
|---|---|---|---|---|---|---|---|---|---|
| Sunday | CA | Berkeley | 2500 LE CONTE AVE | … | 6:00 | 07/23/2017 12:00:00 AM | BURGLARY AUTO | 17091420 | 0 |
| Sunday | CA | Berkeley | BOWDITCH STREET & CHANNING WAY | … | 22:00 | 07/02/2017 0:00 | BURGLARY AUTO | 17038302 | 1 |
2 rows × 12 columns
سنحذف الأعمدة التي لا نحتاجها:
def drop_unneeded_cols(calls):
return calls.drop(columns=['CVDOW', 'InDbDate', 'Block_Location', 'City',
'State', 'EVENTDT', 'EVENTTM'])
الآن نقوم بتطبيق جميع الدوال التي عرفناها سابقاً على البيانات باستخدام pipe: 📝
calls_final = (calls.pipe(combine_event_datetimes)
.pipe(split_lat_lon)
.pipe(match_weekday)
.pipe(drop_unneeded_cols))
df_interact(calls_final)
بنفس الطريقة السابقة سيظهر لنا جدول تفاعلي.

(5508 rows, 8 columns) total
الآن، بيانات المكالمات جاهزة للتحليل. في الجزء التالي، سنقوم بتنظيف بيانات الإيقافات.
calls_final.to_csv('data/calls.csv', index=False)
تنظيف بيانات الإيقافات
لنبدأ تجهيز بيانات ملف الإيقافات للتحليل.
لتحميل الملف: stops.json
نستخدم head لعرض الأسطر الأولى في الملف:
!head data/stops.json
{
"meta" : {
"view" : {
"id" : "6e9j-pj9p",
"name" : "Berkeley PD - Stop Data",
"attribution" : "Berkeley Police Department",
"averageRating" : 0,
"category" : "Public Safety",
"createdAt" : 1444171604,
"description" : "This data was extracted from the Department’s Public Safety Server and covers the data beginning January 26, 2015. On January 26, 2015 the department began collecting data pursuant to General Order B-4 (issued December 31, 2014). Under that order, officers were required to provide certain data after making all vehicle detentions (including bicycles) and pedestrian detentions (up to five persons). This data set lists stops by police in the categories of traffic, suspicious vehicle, pedestrian and bicycle stops. Incident number, date and time, location and disposition codes are also listed in this data.\r\n\r\nAddress data has been changed from a specific address, where applicable, and listed as the block where the incident occurred. Disposition codes were entered by officers who made the stop. These codes included the person(s) race, gender, age (range), reason for the stop, enforcement action taken, and whether or not a search was conducted.\r\n\r\nThe officers of the Berkeley Police Department are prohibited from biased based policing, which is defined as any police-initiated action that relies on the race, ethnicity, or national origin rather than the behavior of an individual or information that leads the police to a particular individual who has been identified as being engaged in criminal activity.",
كما يبدو واضحاً أن الملف ليس من النوع CSV. الملف يحتوي على بيانات من النوع JSON (JavaScript Object Notation) “ترميز الكائنات باستعمال جافا سكريبت”، طريقه كثيرة الاستخدام تُحفظ فيها البيانات على في مصفوفة من النوع Dictionary. مكتبة JSON في بايثون تسهل علينا قراءة هذا النوع من المصفوفات:
تم شرح هذا النوع من المصفوفات Dictionary في الفصل الثالث. تحتوي على مفاتيح Keys وقيم لها Values.
import json
# انتبه ان الملف قد يستهلك جميع ذاكرة الجهاز اذا كان حجمه كبير
# تحققنا من الحجم قبل تحميل الملف
with open('data/stops.json') as f:
stops_dict = json.load(f)
stops_dict.keys()
dict_keys(['meta', 'data'])
لاحظ أننا أظهرنا فقط المفاتيح في المصفوفة stops_dict كي لا نتسبب ببطيء المتصفح أثناء طباعة جميع محتوى المصفوفة. لإلقاء نظره على البيانات دون أن نتسبب بتعطيل المتصفح بسبب حجم البيانات الكبير، يمكننا تحويل المصفوفة إلى نص وطباعة بعض من محتواها:
from pprint import pformat
def print_dict(dictionary, num_chars=1000):
print(pformat(dictionary)[:num_chars])
print_dict(stops_dict['meta'])
عرف الكاتب هنا دالة لطباعة محتوى المصفوفة، تستقبل الدالة المصفوفة + عدد الأحرف التي يرغب بطباعتها
{'view': {'attribution': 'Berkeley Police Department',
'averageRating': 0,
'category': 'Public Safety',
'columns': [{'dataTypeName': 'meta_data',
'fieldName': ':sid',
'flags': ['hidden'],
'format': {},
'id': -1,
'name': 'sid',
'position': 0,
'renderTypeName': 'meta_data'},
{'dataTypeName': 'meta_data',
'fieldName': ':id',
'flags': ['hidden'],
'format': {},
'id': -1,
'name': 'id',
'position': 0,
'renderTypeName': 'meta_data'},
{'dataTypeName': 'meta_data',
'fieldName': ':position',
'flags': ['hidden'],
'format': {},
print_dict(stops_dict['data'], num_chars=300)
[[1,
'29A1B912-A0A9-4431-ADC9-FB375809C32E',
1,
1444146408,
'932858',
1444146408,
'932858',
None,
'2015-00004825',
'2015-01-26T00:10:00',
'SAN PABLO AVE / MARIN AVE',
'T',
'M',
None,
None],
[2,
'1644D161-1113-4C4F-BB2E-BF780E7AE73E',
2,
1444146408,
'932858',
14
يمكن أن نلاحظ أن المفتاح 'meta' يحتوي على وصف البيانات والأعمدة. والمفتاح 'data' يحتوي على البيانات. يمكننا استخدام هذه المعلومة لإنشاء ال DataFrame:
# تحميل البيانات من JSON
# ثم تسمية الأعمدة
stops = pd.DataFrame(
stops_dict['data'],
columns=[c['name'] for c in stops_dict['meta']['view']['columns']])
stops
| Location - Longitude | Location - Latitude | Dispositions | Incident Type | … | created_at | position | id | sid | |
|---|---|---|---|---|---|---|---|---|---|
| None | None | M | T | … | 1444146408 | 1 | 29A1B912-A0A9-4431-ADC9-FB375809C32E | 1 | 0 |
| None | None | M | T | … | 1444146408 | 2 | 1644D161-1113-4C4F-BB2E-BF780E7AE73E | 2 | 1 |
| None | None | M | T | … | 1444146408 | 3 | 5338ABAB-1C96-488D-B55F-6A47AC505872 | 3 | 2 |
| … | … | … | … | … | … | … | … | … | … |
| None | None | BM2TWN; | T | … | 1496269085 | 31079 | C2B606ED-7872-4B0B-BC9B-4EF45149F34B | 31079 | 29205 |
| -122.2865508 | 37.8698757 | HM4TCS; | T | … | 1496269085 | 31080 | 8FADF18D-7FE9-441D-8709-7BFEABDACA7A | 31080 | 29206 |
| -122.2565294 | 37.86720754 | AR; | 1194 | … | 1496269085 | 31081 | F60BD2A4-8C47-4BE7-B1C6-4934BE9DF838 | 31081 | 29207 |
29208 rows × 15 columns
# طباعة اسماء الأعمدة
stops.columns
Index(['sid', 'id', 'position', 'created_at', 'created_meta', 'updated_at',
'updated_meta', 'meta', 'Incident Number', 'Call Date/Time', 'Location',
'Incident Type', 'Dispositions', 'Location - Latitude',
'Location - Longitude'],
dtype='object')
يحتوي الموقع الذي حصلنا على البيانات منه على المعلومات التالية عن الأعمدة:
| النوع | الوصف | العمود |
|---|---|---|
| نص | رقم المخالفة، تم توليد هذا الرقم بشكل تلقائي بواسطة برنامج (CAD) | Incident Number |
| تاريخ + وقت | تاريخ ووقت المخالفة - الإيقاف | Call Date/Time |
| نص | العنوان العام للمخالفة - الإيقاف | Location |
| نص | نوع المخالفة يتم توليده أوتوماتيكياً بواسطة (CAD). الحرف (T) يعني إيقاف سيارة من قبل الشرطة. إيقاف سيارة مشبوهة رمز لها بـ (1196). إيقاف مشاة رمز له (1194). إيقاف دراجة بالرمز (1194B) | Incident Type |
| نص | تصرفات ومعلومات عن الموقوف، مرتبة بالترتيب: أول حرف يعني العرق ، وهو كالتالي: A (آسيوي) B (أسود) H (أسباني) O (آخر) W (أبيض) . الحرف الثاني يعني الجنس: F (أنثى) M (ذكر). الحرف الثالث يعني مدى العمر وهو كالتالي: 1 (أقل من 18) 2 (بين 18-29) 3 (بين 30-39), 4 (أكبر من 40). الحرف الرابع يعني السبب: I (تحقيق) T (إيقاف مروري) R (اشتباه) K (إفراج مشروط) W (مطلوب). الحرف الخامس يعني ما تم تطبيقه على الموقوف: A (اعتقال) C (مخالفه) O (أخرى) W (إنذار). الحرف السادس يوضح إذا تم البحث في السيارة: S (تم البحث) N (لم يتم البحث). معلومات أخرى قد تظهر، منها: P - تقرير الحالة الأولى. M - سرد عن طريق الهاتف فقط. AR - تقرير اعتقال فقط (لم يتم تسليم تقرير القضية). IN - تقرير حادثة. FC - بطاقة ميدانيه. CO - تقرير حادثة تصادم. MH - تقييم نفسي عاجل. TOW - سيارة محجوزة. 0 أو 00000 – الشرطي أوقف لأكثر من خمسة أشخاص | Dispositions |
| رقم | خط العرض العام لموقع المكالمة. هذه المعلومة فقط تم البدء بإضافتها في يناير 2017. | Location - Latitude |
| رقم | خط العرض العام لموقع المكالمة. هذه المعلومة فقط تم البدء بإضافتها في يناير 2017. | Location - Longitude |
نلاحظ أن الموقع لا يحتوي على وصف لأول ثمانية أعمدة لجدول stops. كون هذه الأعمدة تحتوي على بيانات وصفيه metadata لسنا مهتمين بتحليلها في الوقت الحالي. سنقوم بحذف هذه الأعمدة من الجدول:
columns_to_drop = ['sid', 'id', 'position', 'created_at', 'created_meta',
'updated_at', 'updated_meta', 'meta']
# هذه الداله تستقبل DataFrame
# وتقوم بحذف الأعمدة غير المرغوبه منها
# تسجل هذه الأعمدة في المتغير الذي سبق تعريفه columns_to_drop
def drop_unneeded_cols(stops):
return stops.drop(columns=columns_to_drop)
stops = stops.pipe(drop_unneeded_cols)
stops
| Location - Longitude | Location - Latitude | Dispositions | Incident Type | Location | Call Date/Time | Incident Number | |
|---|---|---|---|---|---|---|---|
| None | None | M | T | SAN PABLO AVE / MARIN AVE | 2015-01-26T00:10:00 | 2015-00004825 | 0 |
| None | None | M | T | SAN PABLO AVE / CHANNING WAY | 2015-01-26T00:50:00 | 2015-00004829 | 1 |
| None | None | M | T | UNIVERSITY AVE / NINTH ST | 2015-01-26T01:03:00 | 2015-00004831 | 2 |
| … | … | … | … | … | … | … | … |
| None | None | BM2TWN; | T | UNIVERSITY AVE/6TH ST | 2017-04-30T22:59:26 | 2017-00024245 | 29205 |
| -122.2865508 | 37.8698757 | HM4TCS; | T | UNIVERSITY AVE / WEST ST | 2017-04-30T23:19:27 | 2017-00024250 | 29206 |
| -122.2565294 | 37.86720754 | AR; | 1194 | CHANNING WAY / BOWDITCH ST | 2017-04-30T23:38:34 | 2017-00024254 | 29207 |
29208 rows × 7 columns
كما في بيانات المكالمات، سنجيب على الأسئلة التالية:
- هل توجد بيانات مفقوده؟
- هل توجد أي بيانات مفقوده تم تعبئتها؟ ( مثلاً كتابة رقم 999 لعمر مجهول أو 12:00 صباحاً لتاريخ مجهول)؟
- أي جزء من البيانات أدخلت بواسطة أشخاص حقيقيين؟
هل توجد بيانات مفقوده ؟
يمكن ان نلاحظ ان هناك الكثير من البيانات المفقودة في عمودي خط الطول والعرض. في وصف البيانات ذكر أن العمودان تم البدء في تعبئتها في يناير 2017:
# ستظهر لنا الأسطر التي تحتوي على الأقل على قيمه واحدة مفقوده
null_rows = stops.isnull().any(axis=1)
stops[null_rows]
| Location - Longitude | Location - Latitude | Dispositions | Incident Type | Location | Call Date/Time | Incident Number | |
|---|---|---|---|---|---|---|---|
| None | None | M | T | SAN PABLO AVE / MARIN AVE | 2015-01-26T00:10:00 | 2015-00004825 | 0 |
| None | None | M | T | SAN PABLO AVE / CHANNING WAY | 2015-01-26T00:50:00 | 2015-00004829 | 1 |
| None | None | M | T | UNIVERSITY AVE / NINTH ST | 2015-01-26T01:03:00 | 2015-00004831 | 2 |
| … | … | … | … | … | … | … | … |
| None | None | BM4IWN; | 1194 | 2180 M L KING JR WAY | 2017-04-29T01:59:36 | 2017-00023764 | 29078 |
| None | None | M; | 1194 | 6TH/UNI | 2017-04-30T12:54:23 | 2017-00024132 | 29180 |
| None | None | BM2TWN; | T | UNIVERSITY AVE/6TH ST | 2017-04-30T22:59:26 | 2017-00024245 | 29205 |
25067 rows × 7 columns
يمكن أن نتحقق من بقية الأعمدة إذا كانت تحتوي على بيانات مفقوده:
# ستظهر لنا الأسطر التي تحتوي على الأقل على قيمه واحدة مفقوده
# دون التحقق من المفقودات في عمودي خطوط الطول والعرض
null_rows = stops.iloc[:, :-2].isnull().any(axis=1)
df_interact(stops[null_rows])
بنفس الطريقة السابقة سيظهر لنا جدول تفاعلي.
(63 rows, 7 columns) total
نلاحظ أن أكثر البيانات المفقودة تكون في عمود Dispositions “تصرفات ومعلومات عن الموقوف”. للأسف، لم يتم التوضيح في شرح البيانات سبب فقدان هذه المعلومات. بما أن عدد البيانات المفقودة 63 مقارنة بمجموع البيانات 25000 في الجدول، سنكمل تنظيف البيانات مع الأخذ بالاعتبار أن البيانات المفقودة قد تؤثر على نتائجنا.
هل توجد أي بيانات مفقوده تم تعبئتها ؟
لا يبدو لدينا أن أي من البيانات المفقودة تم تعبئتها. على عكس بيانات المكالمات، التي تم فيها تقسيم التاريخ والوقت في أعمدة منفصله، في جدول الإيقافات يظهر التاريخ والوقت في عمود واحد.
أي جزء من البيانات أدخلت بواسطة أشخاص حقيقيين ؟
أيضاً، كما في بيانات المكالمات، يبدو أن الكثير من بيانات الإيقافات تم تعبئتها بشكل تلقائي بواسطة الآلة أو تم اختيارها من قوائم محددة مسبقاً بواسطة أشخاص ( مثل عمود Incident Type “نوع المخالفه” ).
نلاحظ أن عمود العنوان لا يحتوي على بيانات محددة مسبقاً من قوائم. يمكننا التحقق لنرى بعض الأخطاء الإملائية في كتابة العناوين:
stops['Location'].value_counts()
2200 BLOCK SHATTUCK AVE 229
37.8693028530001~-122.272234021 213
UNIVERSITY AVE / SAN PABLO AVE 202
...
VALLEY ST / DWIGHT WAY 1
COLLEGE AVE / SIXTY-THIRD ST 1
GRIZZLY PEAK BLVD / MARIN AVE 1
Name: Location, Length: 6393, dtype: int64
كما يظهر، يبدو أنه في مرات تم إدخال العنوان كاملاً، أو التقاطعات، ومرات أخرى تم إدخال خطوط الطول والعرض. للأسف ليس لدينا بيانات كاملة لخطوط الطول والعرض لاستخدامها بدلاً من العناوين في هذا العمود. قد نحتاج لتنظيف هذا العمود يدوياً إذا ما أردنا تحليل بياناته.
يمكننا أيضاً التحقق من عمود Dispositions:
dispositions = stops['Dispositions'].value_counts()
interact(lambda row=0: dispositions.iloc[row:row+7],
row=(0, len(dispositions), 7))
بنفس الطريقة السابقة سيظهر لنا جدول تفاعلي بالأنواع المختلفة لتصرفات ومعلومات الموقوف
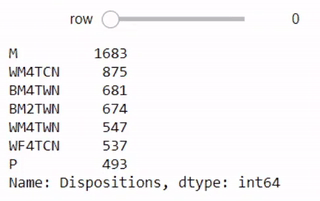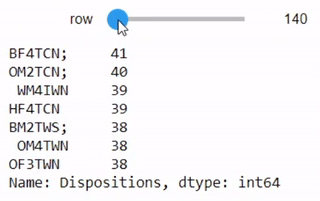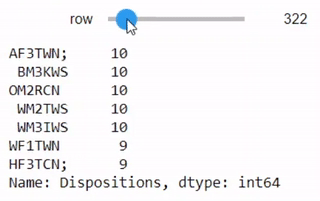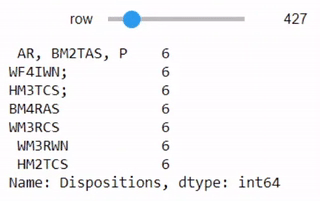
يحتوي العمود على الكثير من التناقضات والاختلافات في تسجيل البيانات. مثلاً، في بعض الأحيان يتم إضافة مسافة قبل إدخال البيانات، وبعض المرات يتم إضافة فاصلة منقوطة في النهاية. بعض الأسطر أيضاً تحتوي على أكثر من إدخال. التنوع في البيانات يوضح أنها قد تكون أدخلت بواسطة أشخاص حقيقيين وليس الآلة، لذا يجب علينا الحذر عند العمل عليها:
# امثله على قيم تحتوي على مشاكل
dispositions.iloc[[0, 20, 30, 266, 1027]]
M 1683
M; 238
M 176
HF4TWN; 14
OM4KWS 1
Name: Dispositions, dtype: int64
أيضاً، أكثر القيم تكراراً هو M وهو كقيمه أولاً لا تعتبر صحيحه لأنه ليس من قائمة الخيارات في العرق. هذا يقترح أن تم تغير طريقة إدخال البيانات في هذا العمود بعد فترة من بدأ الإدخال، أو أنه مسموح لمدخل البيانات إدخال قيم دون التحقق أن كانت تطابق شروط الإدخال في العمود. على أية حال، سيشكل العمل على هذا العمود تحدي كبير.
يمكننا البدء بخطوات بسيطه لتنظيف هذا العمود عن طريق حذف المسافات الفارغة أن كانت في البداية أو النهاية، حذف الفواصل المنقوطة إذا كانت في آخر الجملة، وإذا تكررت الفاصلة المنقوطة في نفس السطر نستبدها بفاصلة عادية:
def clean_dispositions(stops):
cleaned = (stops['Dispositions']
.str.strip() # حذف المسافات الفارغه ان كانت في البدايه او النهايه
.str.rstrip(';') # حذف الفواصل المنقوطه اذا كانت في آخر الجمله
.str.replace(';', ',')) # تبديل باقي الفواصل المنقوطه إلى فواصل
return stops.assign(Dispositions=cleaned)
stops_final = (stops
.pipe(drop_unneeded_cols)
.pipe(clean_dispositions))
df_interact(stops_final)
بنفس الطريقة السابقة سيظهر لنا جدول تفاعلي كالتالي
(29208 rows, 7 columns) total
الملخص
كما رأينا، كلا الملفين وضحت كيف أن تنظيف البيانات أحياناً يكون صعباً ومملاً. تنظيف البيانات بشكل كامل يأخذ وقتاً طويل، ولكن عدم تنظيفها قد يوصلنا لنتائج خاطئة. عند مواجهة بيانات يجب أن نحدد خياراتنا ونحقق التوازن في خطوات تنظيف البيانات حتى نحصل على نتائج صحيحه. القرارات التي نتخذها أثناء تنظيف البيانات تأثر على تحليلنا. مثلاً، قررنا عدم تنظيف عمود Location في بيانات الإيقافات، لذا يجب أن نحذر أثناء تحليله. يجب علينا تسجيل كل قرار اتخذناه أثناء تنظيف البيانات ليكون مرجع لنا لاحقاً، والأفضل يكون في ملف جوبتر مع الكود البرمجي كي يكونا كليهما أمامنا وقت المراجعة.
stops_final.to_csv('stops.csv', index=False)
هيكلة وربط البيانات
الهيكل
هيكل Structure البيانات يعني شكل ملف البيانات. بشكل أبسط، يعني الطريقة التي أدخلت فيها البيانات في الملف. مثلاً، شاهدنا في ملف بيانات المكالمات أن الملف من النوع CSV:
!head data/Berkeley_PD_-_Calls_for_Service.csv
CASENO,OFFENSE,EVENTDT,EVENTTM,CVLEGEND,CVDOW,InDbDate,Block_Location,BLKADDR,City,State
17091420,BURGLARY AUTO,07/23/2017 12:00:00 AM,06:00,BURGLARY - VEHICLE,0,08/29/2017 08:28:05 AM,"2500 LE CONTE AVE
Berkeley, CA
(37.876965, -122.260544)",2500 LE CONTE AVE,Berkeley,CA
17020462,THEFT FROM PERSON,04/13/2017 12:00:00 AM,08:45,LARCENY,4,08/29/2017 08:28:00 AM,"2200 SHATTUCK AVE
Berkeley, CA
(37.869363, -122.268028)",2200 SHATTUCK AVE,Berkeley,CA
17050275,BURGLARY AUTO,08/24/2017 12:00:00 AM,18:30,BURGLARY - VEHICLE,4,08/29/2017 08:28:06 AM,"200 UNIVERSITY AVE
Berkeley, CA
(37.865491, -122.310065)",200 UNIVERSITY AVE,Berkeley,CA
وبيانات الإيقافات من النوع JSON:
# عرض اول واخر خمس اسطر
!head -n 5 data/stops.json
!echo '...'
!tail -n 5 data/stops.json
{
"meta" : {
"view" : {
"id" : "6e9j-pj9p",
"name" : "Berkeley PD - Stop Data",
...
, [ 31079, "C2B606ED-7872-4B0B-BC9B-4EF45149F34B", 31079, 1496269085, "932858", 1496269085, "932858", null, "2017-00024245", "2017-04-30T22:59:26", " UNIVERSITY AVE/6TH ST", "T", "BM2TWN; ", null, null ]
, [ 31080, "8FADF18D-7FE9-441D-8709-7BFEABDACA7A", 31080, 1496269085, "932858", 1496269085, "932858", null, "2017-00024250", "2017-04-30T23:19:27", " UNIVERSITY AVE / WEST ST", "T", "HM4TCS; ", "37.8698757000001", "-122.286550846" ]
, [ 31081, "F60BD2A4-8C47-4BE7-B1C6-4934BE9DF838", 31081, 1496269085, "932858", 1496269085, "932858", null, "2017-00024254", "2017-04-30T23:38:34", " CHANNING WAY / BOWDITCH ST", "1194", "AR; ", "37.867207539", "-122.256529377" ]
]
}
بالطبع هناك أنواع أخرى لأشكال ملف البيانات، هذه قائمة للأكثر استخداماً:
- Comma-Separated Values (CSV) و Tab-Separated Values (TSV). هذان النوعان عادةً ما تحتوي على بيانات بشكل جداول. في هذه الملفات كل سطر يمثل صف; ويفصل بين البيانات بعلامة الفاصلة ( , ) أو علامة Tab ( \t ). العمل على هذه الملفات يعتبر سهل جداً لأن شكلها مشابه بشكل كبير للـ DataFrame في بانداز. 📝
- JavaScript Object Format (JSON) ملفات JSON تكون ذات هيكل هرمي وتحتوي على مفاتيح Keys وقيم Values. نحتاج لقراءة الملف بشكل كامل كقاموس Dictionary في لغة بايثون ومن ثم نبحث عن طريقه لاستخراج القيم إلى DataFrame. 📝
- eXtensible Markup Language (XML) و HyperText Markup Language (HTML) هذه الملفات هرمية وتتبع طريقة المفاتيح والقيم. مثال عليها: 📝
<?xml version="1.0" encoding="UTF-8"?>
<note>
<to>Tove</to>
<from>Jani</from>
<heading>Reminder</heading>
<body>Don't forget me this weekend!</body>
</note>
في فصل لاحق، سنستخدم XPath لاستخراج البيانات من هذا النوع من الملفات.
- بيانات الإدخال Log Data. الكثير من البرامج يمكنها تصدير البيانات على شكل نصوص غير مهيكلة، مثلاً:
2005-03-23 23:47:11,663 - sa - INFO - creating an instance of aux_module.Aux
2005-03-23 23:47:11,665 - sa.aux.Aux - INFO - creating an instance of Aux
2005-03-23 23:47:11,665 - sa - INFO - created an instance of aux_module.Aux
2005-03-23 23:47:11,668 - sa - INFO - calling aux_module.Aux.do_something
2005-03-23 23:47:11,668 - sa.aux.Aux - INFO - doing something
في فصل لاحق، سنستخدم التعابير النمطية Regular Expressions لاستخراج البيانات من هذا النوع من الملفات.
الربط
في العادة تكون البيانات مقسمه في أكثر من جدول. مثلاً، الجدول الأول يحتوي على معلومات الأشخاص، والجدول الثاني يحتوي على البريد الإلكتروني لكل شخص:
people = pd.DataFrame(
[["Joey", "blue", 42, "M"],
["Weiwei", "blue", 50, "F"],
["Joey", "green", 8, "M"],
["Karina", "green", 7, "F"],
["Nhi", "blue", 3, "F"],
["Sam", "pink", -42, "M"]],
columns = ["Name", "Color", "Number", "Sex"])
people
| Sex | Number | Color | Name | |
|---|---|---|---|---|
| M | 42 | blue | Joey | 0 |
| F | 50 | blue | Weiwei | 1 |
| M | 8 | green | Joey | 2 |
| F | 7 | green | Karina | 3 |
| F | 3 | blue | Nhi | 4 |
| M | -42 | pink | Sam | 5 |
email = pd.DataFrame(
[["Deb", "deborah_nolan@berkeley.edu"],
["Sam", "samlau95@berkeley.edu"],
["John", "doe@nope.com"],
["Joey", "jegonzal@cs.berkeley.edu"],
["Weiwei", "weiwzhang@berkeley.edu"],
["Weiwei", "weiwzhang+123@berkeley.edu"],
["Karina", "kgoot@berkeley.edu"]],
columns = ["User Name", "Email"])
email
| User Name | ||
|---|---|---|
| deborah_nolan@berkeley.edu | Deb | 0 |
| samlau95@berkeley.edu | Sam | 1 |
| doe@nope.com | John | 2 |
| jegonzal@cs.berkeley.edu | Joey | 3 |
| weiwzhang@berkeley.edu | Weiwei | 4 |
| weiwzhang+123@berkeley.edu | Weiwei | 5 |
| kgoot@berkeley.edu | Karina | 6 |
لربط كل شخص ببريده الإلكتروني، يمكننا جمع الجدولين في جدول واحد والربط بينهم بواسطة عمود اسم المستخدم. يجب أن نقرر ما نفعله للأشخاص الذين يظهرون في جدول دون الآخر. مثلاً، Fernando ظهر في جدول الأشخاص people ولم يظهر في جدول البريد الإلكتروني email. لدينا أنواع مختلفة من خيارات الربط Join، ولكل نوع طريقه مختلفة في التعامل مع البيانات المفقودة في جدول عن الآخر. أحد أشهر أنواع الربط هي Inner Join الربط الداخلي، وفيه أي سطر لا يوجد له قيمه في الجدول الآخر يتم حذفه:
# Fernando, Nhi, Deb, و John لا يظهران في جدول البريد الإلكتروني لذا تم حذفهم
people.merge(email, how='inner', left_on='Name', right_on='User Name')
| User Name | Sex | Number | Color | Namr | ||
|---|---|---|---|---|---|---|
| jegonzal@cs.berkeley.edu | Joey | M | 42 | blue | Joey | 0 |
| jegonzal@cs.berkeley.edu | Joey | M | 8 | green | Joey | 1 |
| weiwzhang@berkeley.edu | Weiwei | F | 50 | blue | Weiwei | 2 |
| weiwzhang+123@berkeley.edu | Weiwei | F | 50 | blue | Weiwei | 3 |
| kgoot@berkeley.edu | Karina | F | 7 | green | Karina | 4 |
| samlau95@berkeley.edu | Sam | M | -42 | pink | Sam | 5 |
توجد أربع أنواع للربط التي تستخدم بشكل معتاد ودائم: الربط الداخلي Inner Join، الربط الكامل Full Join ( و أحياناً يطلق عليه الخارجي Outer Join)، الربط اليساري Left Join, الربط اليميني Right Join. في الأسفل رسم بياني يوضح الفرق بين كل نوع.
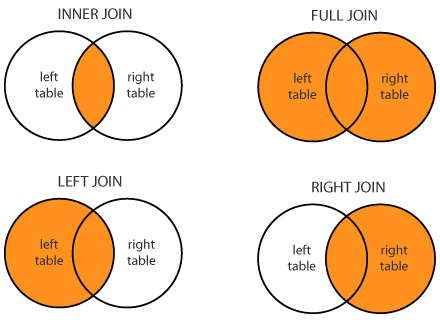
شرح مبسط للفرق بين كل نوع. أولاً، حددنا الجدول على اليسار هو
peopleوعلى اليمين هوemails. لدينا شرط في الأمر السابق، وهو أن يتوافق كل اسم'left_on='Nameفي جدول الأشخاصpeopleمع اسم المستخدم'right_on='User Nameفي جدول البريد الإلكترونيhowفي المثال اخترناinner: 📝 📝 📝people.merge(email, how='inner', left_on='Name', right_on='User Name')
- Inner Join الربط الداخلي: سيتحقق الشرط من توفر القيم في كلا الجدولين. في حال وجد قيمه موجودة في جدول دون الآخر فسيتم تجاهلها.
- Full Join (Outer) الربط الكامل (الخارجي): يربط بين كل القيم سواء طابقت للشرط الذي حددناه أو لم تطابق، القيم التي تتوفر في جدول دون الآخر يتم إضافتها أيضاً وتضاف قيمه NaN للأعمدة التي لا تحتوي على قيم.
- Left Join الربط اليساري: يتم استخدام كل القيم في الجدول على اليسار (في مثالنا هنا جدول
people) سواء تحتوي على قيم في الجدول الآخر أو لا، بينما يتم جلب القيم التي توافق الشرط الذي حددنا من الجدول على اليمين (في مثالنا هنا جدول- Right Join الربط اليميني: عكس الربط اليساري، في مثالنا هنا يتم جلب جميع القيم في الجدول
peopleيتم استخدام فقط القيم التي توافق الشرط، وهي القيم التي تحتوي على أسماء مستخدمين موجودة في الجدول
قائمة المراجعة لهيكل البيانات
بعد مراجعتك لهيكل البيانات، يجب عليك الإجابة على الأسئلة التالية. سنجيب عن الأسئلة باستخدام بيانات المكالمات والإيقافات.
هل البيانات منسقه بشكل أو ترميز أساسي/عام؟
الأنواع الأساسيه تشمل:
- البيانات المجدولة: CSV, TSV, Excel, SQL.
- البيانات الهرمية: JSON, XML.
بيانات المكالمات جاءت على شكل CSV وبيانات الإيقافات على شكل JSON.
هل البيانات مُرتبه على شكل صفوف؟ إذا كان الجواب لا، هل يمكننا معرفة الأسطر عند مراجعة البيانات؟
بيانات المكالمات جاءت على شكل أسطر، بينما قمنا باستخراج الأسطر في بيانات الإيقافات.
هل البيانات هرمية؟ هل يمكننا تفكيكها؟
بيانات المكالمات ليست هرمية، لم يتعين علينا العمل بشكل كبير على بيانات الإيقافات لتفكيك هرميتها.
هل أضيف للبيانات أي مراجع؟ إذا كان كذلك، هل يمكننا ربطها بالبيانات؟
بيانات المكالمات أضافت جدول أيام الأسبوع كمرجع. ربط وجمع الجدولين معاً أضاف لنا أيام الأسبوع لكل مخالفه. لم يتم ذكر أي مرجع لبيانات الإيقافات.
ما هي الأعمدة في كل جدول؟ ما نوع كل عمود؟
تم وصف وشرح كل نوع من الأعمدة في خطوة تنظيف البيانات لكل جدول. هنا لبيانات المكالمات، وهنا لبيانات الإيقافات.
جودة البيانات
جودة البيانات تعني ما يمثله كل سطر في بياناتك. مثلاً، في بيانات المكالمات كل سطر يمثل حاله واحدة لمكالمة الشرطة:
calls = pd.read_csv('data/calls.csv')
calls.head()
| Day | Longitude | Latitude | EVENTDTTM | BLKADDR | CVLEGEND | OFFENSE | CASENO | |
|---|---|---|---|---|---|---|---|---|
| Sunday | -122.260544 | 37.876965 | 23/07/2017 6:00 | 2500 LE CONTE AVE | BURGLARY - VEHICLE | BURGLARY AUTO | 17091420 | 0 |
| Sunday | -122.256554 | 37.867209 | 02/07/2017 22:00 | BOWDITCH STREET & CHANNING WAY | BURGLARY - VEHICLE | BURGLARY AUTO | 17038302 | 1 |
| Sunday | -122.250664 | 37.867948 | 20/08/2017 23:20 | 2900 CHANNING WAY | LARCENY | THEFT MISD. (UNDER $950) | 17049346 | 2 |
| Sunday | -122.266672 | 37.856719 | 09/07/2017 4:15 | 2100 RUSSELL ST | LARCENY | THEFT MISD. (UNDER $950) | 17091319 | 3 |
| Sunday | -122.258994 | 37.867816 | 30/07/2017 1:16 | TELEGRAPH AVENUE & DURANT AVE | DISORDERLY CONDUCT | DISTURBANCE | 17044238 | 4 |
في بيانات الإيقافات كل سطر يعني حالة إيقاف من قبل الشرطة:
stops = pd.read_csv('data/stops.csv', parse_dates=[1], infer_datetime_format=True)
stops.head()
| Location - Longitude | Location - Latitude | Dispositions | Incident Type | Location | Call Date/Time | Incident Number | |
|---|---|---|---|---|---|---|---|
| NaN | NaN | M | T | SAN PABLO AVE / MARIN AVE | 26/01/2015 0:10 | 2015-00004825 | 0 |
| NaN | NaN | M | T | SAN PABLO AVE / CHANNING WAY | 26/01/2015 0:50 | 2015-00004829 | 1 |
| NaN | NaN | M | T | UNIVERSITY AVE / NINTH ST | 26/01/2015 1:03 | 2015-00004831 | 2 |
| NaN | NaN | BM4ICN | 1194 | 2000 BLOCK BERKELEY WAY | 26/01/2015 7:16 | 2015-00004848 | 3 |
| NaN | NaN | BM4ICN | 1194 | 1700 BLOCK SAN PABLO AVE | 26/01/2015 7:43 | 2015-00004849 | 4 |
يمكن أن تأتينا بيانات الإيقافات بشكل آخر كالتالي:
(stops
.groupby(stops['Call Date/Time'].dt.date)
.size()
.rename('Num Incidents')
.to_frame()
)
| Num Incidents | |
|---|---|
| Call Date/Time | |
| 46 | 26/01/2015 |
| 57 | 27/01/2015 |
| 56 | 28/01/2015 |
| … | … |
| 82 | 28/04/2017 |
| 86 | 29/04/2017 |
| 59 | 30/04/2017 |
825 rows × 1 columns
في هذه الحالة، كل سطر يعني حالات الإيقاف التي تمت في ذلك التاريخ. يمكن أن نوصف هذا الجدول بجدول ذو جودة رديئه مقارنة بالجدول الذي سبقه. من المهم معرفة جودة البيانات لأنها تحدد نوع التحليل الذي سوف تقوم به. بشكل عام، كل ما كانت جودة البيانات أفضل كان العمل عليها أفضل، على الرغم أن بإمكاننا استخدام التجميع والجداول المحورية لتحويل بيانات من جيدة إلى رديئه، يمكننا تحويل بيانات رديئه إلى جيدة باستخدام بعض الأدوات.
قائمة المراجعة لجودة البيانات
يجب عليك الإجابة على الأسئلة التالية بعد التحقق من جودة البيانات. سنجيب على الأسئلة لبيانات المكالمات والإيقافات.
ماذا يمثل كل سطر؟
في بيانات المكالمات، كل سطر يمثل حاله واحدة لمكالمة الشرطة. في بيانات الإيقافات، كل سطر يمثل حالة إيقاف من قبل الشرطة.
هل كل البيانات تملك نفس الجودة؟ (أحياناً الجدول يحتوي على أسطر مجاميع)
نعم، لجدولي المكالمات والإيقافات.
إذا كانت البيانات عبارة عن مجاميع، كيف تم جمعها؟ العينات والمتوسطات أحد أكثر أمثلة التجميع استخداماً
على حسب رؤيتنا للبيانات، لا تحتوي على مجاميع. سنأخذ بعين الاعتبار أن بيانات الموقع هي عبارة عن أسماء الأحياء بدلاً من عناوين معينة.
أي نوع من التجميع يمكننا تطبيقه على البيانات؟
مثلاً، أحد المعلومات التي يمكننا الاستفادة منها هي التجميع بين الأشخاص ومواقع البيانات أو الأحداث لإيجاد المجاميع خلال فترة معينة.
في هذا المثال، يمكننا الجمع بناءاً على التاريخ أو الوقت. مثلا، يمكننا إيجاد الأوقات التي يكثر فيها الحالات يومياً. يمكننا أيضاً الجمع بواسطة نوع المخالفات وموقعها لمعرفة في أي مواقع بيركلي تكثر الحوادث.
مدى البيانات
تحتاج لتحميل البيانات بعد القيام بعملية التنظيف في درسي تنظيف بيانات المكالمات و تنظيف بيانات الإيقافات، أو تحميلها هنا:
مدى البيانات هو مدى قدرة البيانات على تغطية ما نحتاجه للقيام بالتحليل. نحاول الإجابة على الأسئلة التالية لمعرفة مدى بياناتنا:
يقصد الكاتب بالمدى Scope ما إذا كانت البيانات شاملة ومفيده لنقوم بتحليلها ونجيب على الأسئلة التي وضعناها باستخدام البيانات.
هل تغطي البيانات المواضيع التي تهمنا؟
مثلاً، بيانات المكالمات والإيقافات تحتوي على جميع الحالات في مدينة بيركلي. إذا كنا مهتمين بحالات الجرائم في ولاية كاليفورنيا، فهذه البيانات لن تفيدنا كونها محدودة المدى.
بشكل عام، كلما كان المدى أكبر، كلما أصبح أكثر فائدة لأن بإمكاننا فلترة البيانات الكبيرة لعده مداءات صغيرة ولا يمكننا عمل العكس، تحويل المداءات الصغيرة إلى كبيرة. مثلاً، إذا كانت لدينا بيانات الإيقافات في الولايات المتحدة، يمكننا فلترة وتقسيم البيانات لنقوم بتحليلنا على بيانات بيركلي.
خذ بعين الاعتبار، أن المدى مصطلح عام وليس مخصص فقط للمواقع الجغرافية. مثلاً، يمكن استخدامه مع الوقت، بيانات المكالمات تحتوي على بيانات 180 يوم فقط.
عاده ما نقوم بالتحقق من المدى عندما نقوم بالكشف عن طريقة توليد البيانات ونقوم بالتأكد من المدى في خطوة التحليل الاستكشافي للبيانات. لنتحقق من مدى الموقع الجغرافي والوقت في بيانات المكالمات:
calls = pd.read_csv('data/calls.csv', parse_dates=['EVENTDTTM'], infer_datetime_format=True)
stops = pd.read_csv('data/stops.csv', parse_dates=[1], infer_datetime_format=True)
calls
| Day | Longitude | Latitude | EVENTDTTM | BLKADDR | CVLEGEND | OFFENSE | CASENO | |
|---|---|---|---|---|---|---|---|---|
| Sunday | -122.260544 | 37.876965 | 23/07/2017 6:00 | 2500 LE CONTE AVE | BURGLARY - VEHICLE | BURGLARY AUTO | 17091420 | 0 |
| Sunday | -122.256554 | 37.867209 | 02/07/2017 22:00 | BOWDITCH STREET & CHANNING WAY | BURGLARY - VEHICLE | BURGLARY AUTO | 17038302 | 1 |
| Sunday | -122.250664 | 37.867948 | 20/08/2017 23:20 | 2900 CHANNING WAY | LARCENY | THEFT MISD. (UNDER $950) | 17049346 | 2 |
| … | … | … | … | … | … | … | … | … |
| Friday | -122.270671 | 37.896218 | 31/03/2017 0:00 | 100 MONTROSE RD | FRAUD | IDENTITY THEFT | 17021604 | 5505 |
| Friday | -122.254552 | 37.868957 | 09/06/2017 22:34 | 2300 COLLEGE AVE | DISORDERLY CONDUCT | DISTURBANCE | 17033201 | 5506 |
| Friday | -122.288038 | 37.869679 | 11/08/2017 20:00 | UNIVERSITY AVENUE & CHESTNUT ST | BURGLARY - VEHICLE | BURGLARY AUTO | 17047247 | 5507 |
5508 rows × 8 columns
# عرض اقرب وابعد تاريخ في بيانات المكالمات
calls['EVENTDTTM'].dt.date.sort_values()
1384 2017-03-02
1264 2017-03-02
1408 2017-03-02
...
3516 2017-08-28
3409 2017-08-28
3631 2017-08-28
Name: EVENTDTTM, Length: 5508, dtype: object
calls['EVENTDTTM'].dt.date.max() - calls['EVENTDTTM'].dt.date.min()
datetime.timedelta(179)
يحتوي الجدول على بيانات 179 يوم وهي قريباً بشكل كبير إلى 180 يوماً التي ذكرت في وصف البيانات، لذا نتوقع أن أحد الأيام مر دون القيام بأي مكالمه، لذا نتوقع أن اليوم الذي لم يحصل فيه أي مكالمه اما 14 أبريل 2017 او 29 أغسطس 2017
للتحقق من مدى المواقع الجغرافيه سنستخدم الخريطه:
import folium # سنستخدم مكتبة Folium لرسم الخريطه
import folium.plugins
SF_COORDINATES = (37.87, -122.28)
sf_map = folium.Map(location=SF_COORDINATES, zoom_start=13)
locs = calls[['Latitude', 'Longitude']].astype('float').dropna().to_numpy()
heatmap = folium.plugins.HeatMap(locs.tolist(), radius = 10)
sf_map.add_child(heatmap)
مع القليل من الإستثناءات، بيانات المكالمات تغطي مدينة بيركلي بشكل كامل. نلاحظ ان اكثر المكالمات كانت من وسط مدينة بيركلي وجنوب الحرم الجامعي لجامعة بيركلي.
لنتحقق من بيانات الإيقافات لتحديد مداها الزمني والجغرافي:
stops
| Location - Longitude | Location - Latitude | Dispositions | Incident Type | Location | Call Date/Time | Incident Number | |
|---|---|---|---|---|---|---|---|
| NaN | NaN | M | T | SAN PABLO AVE / MARIN AVE | 26/01/2015 0:10 | 2015-00004825 | 0 |
| NaN | NaN | M | T | SAN PABLO AVE / CHANNING WAY | 26/01/2015 0:50 | 2015-00004829 | 1 |
| NaN | NaN | M | T | UNIVERSITY AVE / NINTH ST | 26/01/2015 1:03 | 2015-00004831 | 2 |
| … | … | … | … | … | … | … | … |
| NaN | NaN | BM2TWN | T | UNIVERSITY AVE/6TH ST | 30/04/2017 22:59 | 2017-00024245 | 29205 |
| -122.286551 | 37.869876 | HM4TCS | T | UNIVERSITY AVE / WEST ST | 30/04/2017 23:19 | 2017-00024250 | 29206 |
| -122.256529 | 37.867208 | AR | 1194 | CHANNING WAY / BOWDITCH ST | 30/04/2017 23:38 | 2017-00024254 | 29207 |
29208 rows × 7 columns
stops['Call Date/Time'].dt.date.sort_values()
0 2015-01-26
25 2015-01-26
26 2015-01-26
...
29175 2017-04-30
29177 2017-04-30
29207 2017-04-30
Name: Call Date/Time, Length: 29208, dtype: object
كما ذُكر لنا، تم البدء بتجميع البيانات من تاريخ 26 يناير 2015. ويبدو ان تم تحميل البيانات في بداية شهر مايو 2017 كون ان اخر تاريخ في البيانات كان 30 ابريل 2017. لنقم برسم الخريطة للتحقق من المدى الجغرافي:
SF_COORDINATES = (37.87, -122.28)
sf_map = folium.Map(location=SF_COORDINATES, zoom_start=13)
locs = stops[['Location - Latitude', 'Location - Longitude']].astype('float').dropna().to_numpy()
heatmap = folium.plugins.HeatMap(locs.tolist(), radius = 10)
sf_map.add_child(heatmap)
تأكد لنا الخريطة أن بيانات الإيقافات هي لمدينة بيركلي، وان أكثر الإيقافات كانت في وسط وغرب المدينة.
زمانية البيانات
يقصد بزمانية البيانات هنا بكيفية بناء الوقت والتاريخ في البيانات. نحاول الإجابة عن الأسئلة التالية:
ما معنى أعمدة التاريخ والوقت في البيانات؟
في بيانات المكالمات والإيقافات، بيانات التاريخ والوقت توضح متى تم إجراء المكالمة أو متى تم الإيقاف بواسطة الشرطة. ولكن، بيانات الإيقافات تحتوي أيضاً على أعمدة تاريخ ووقت توضح متى تم إدخال القضية إلى قاعدة البيانات والتي قمنا بحذفها أثناء قيمنا بتنظيف البيانات لأننا رأينا عدم أهميتها لتحليلنا.
أيضاً، يجب علينا الحذر والتحقق من المنطقة الزمنية والتوقيت الصيفي لأعمدة الوقت والتاريخ عند العمل على بيانات تم سحبها من أكثر من موقع.
كيف تم تمثيل التاريخ والوقت في البيانات؟
رغم أن الولايات المتحدة تستخدم النمط MM/DD/YYYY، الكثير من دول العالم تستخدم DD/MM/YYYY. هناك الكثير من الأنماط الأخرى حول العالم ويجب الحذر ومعرفة تلك الأنماط أثناء تحليل البيانات.
في بيانات المكالمات والإيقافات، التواريخ تأتي بالنمط MM/DD/YYYY.
هل هناك انماط زمنيه قد تظهر كقيم غير موجوده؟
بعض البرامج تستخدم أنماط سبق تعرفيها كقيم غير موجودة Null. مثلاً برنامج أكسل يستخدم التاريخ Jan 1st, 1990 ، ونفس البرنامج على أجهزة الماكنتوش يستخدم التاريخ Jan 1st, 1904. الكثير من البرامج الأخرى تقوم بإنشاء وقت وتاريخ بشكل تلقائي 12:00am Jan 1st, 1970 أو 11:59pm Dec 31st, 1969 كون ذلك هو نمط البداية بتوقيت يونكس. إذا لاحظت تكرار هذه القيمة أكثر من مرة في بياناتك، فيجب عليك الحذر ومراجعة مصدر البيانات. لا تحتوي بيانات المكالمات والإيقافات على أي من هذه القيم المشبوهة.
مدى ثقتنا بالبيانات
نطلق على بيانات أنها موثوقة إذا كنا نعتقد أنها تصف الحقيقة بشكل كامل. عادةً البيانات غير الموثوقة تحتوي على التالي:
أرقام غير واقعية أو غير حقيقية
مثلاً، احتواء البيانات على تواريخ مستقبليه، مواقع جغرافية غير موجودة، أرقام سلبية أو قيم شاذة كثيره.
قيم تعتمد على قيم أخرى لكن لا تتوافق معها
مثلاً، تاريخ الميلاد والعمر لا يتطابقان.
بيانات مُدخله يدوياً
كما رأينا سابقاً، هذا النوع من البيانات عاده ما يحتوي على الكثير من الأخطاء الإملائية والتناقضات.
علامات واضحة بوجود بيانات مزورة
مثلاً، تكرار بالأسماء، أو معلومات بريد إلكتروني تبدو غير حقيقة.
لاحظ التشابه الكثير بعمليات تنظيف البيانات. كما ذكرنا سابقاً، عادةً ما نتنقل بين تنظيف البيانات والتحليل الاستكشافي للبيانات، خاصة عندما نحدد مدى ثقتنا بالبيانات. مثلاً، الرسم البياني عادةً ما يساعد باكتشاف القيم الغريبة في البيانات:
calls = pd.read_csv('data/calls.csv')
calls.head()
| Day | Longitude | Latitude | BLKADDR | … | EVENTTM | EVENTDT | OFFENSE | CASENO | |
|---|---|---|---|---|---|---|---|---|---|
| Sunday | -122.260544 | 37.876965 | 2500 LE CONTE AVE | … | 6:00 | 07/23/2017 12:00:00 AM | BURGLARY AUTO | 17091420 | 0 |
| Sunday | -122.256554 | 37.867209 | BOWDITCH STREET & CHANNING WAY | … | 22:00 | 07/02/2017 0:00 | BURGLARY AUTO | 17038302 | 1 |
| Sunday | -122.250664 | 37.867948 | 2900 CHANNING WAY | … | 23:20 | 08/20/2017 12:00:00 AM | THEFT MISD. (UNDER $950) | 17049346 | 2 |
| Sunday | -122.266672 | 37.856719 | 2100 RUSSELL ST | … | 4:15 | 07/09/2017 0:00 | THEFT MISD. (UNDER $950) | 17091319 | 3 |
| Sunday | -122.258994 | 37.867816 | TELEGRAPH AVENUE & DURANT AVE | … | 1:16 | 07/30/2017 12:00:00 AM | DISTURBANCE | 17044238 | 4 |
5 rows × 9 columns
calls['CASENO'].plot.hist(bins=30)
<matplotlib.axes._subplots.AxesSubplot at 0x1a1ebb2898>
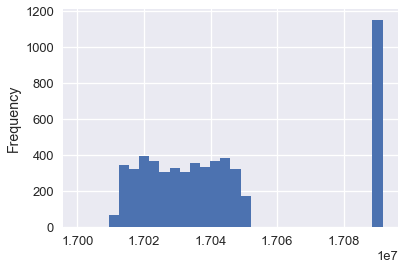
لاحظ المجموعات الغير متوقعة بين 17030000 و 1709000. عن طريق رسم توزيع البيانات لأرقام الحالات، نلاحظ مباشرةً الشذوذ في البيانات. في هذه الحالة، يمكننا توقع أنه يوجد فريقين مختلفين في قسم الشرطة يستخدمون أنواع مختلفة لأرقام الحالات في مكالماتهم.
استكشاف البيانات عادةً ما يظهر أسباب الشذوذ فيها، إذا كان بالإمكان إصلاحها، يمكننا تطبيق تقنيات تنظيف البيانات عليها.